
Course: Implement Apache Hadoop for Big Data













หลักสูตรอบรม : Implement Apache Hadoop for Big Data
ระยะเวลา: 3 วัน (18 ชม.) 9.00 - 16.00 น.
ราคาอบรม ต่อ ท่าน (Public Training) : 15,000 บาท (online) / 17,000 บาท (onsite)
กรณีเป็น In-house Training จะคำนวณราคาตามเงื่อนไขของงานอบรม
*ราคาดังกล่าวยังไม่รวมภาษีมูลค่าเพิ่ม*
Public Training หมายถึง การอบรมให้กับบุคคล/บริษัท ทั่วไป ที่มีความสนใจอบรมในวิชาเดียวกัน โดยจะมี 2 แบบ
1. อบรมแบบ Online โดย Live ผ่านโปรแกรม Zoom พร้อมทำ Workshop ร่วมกันกับวิทยากร
2. อบรมแบบ Onsite ณ ห้องอบรม ที่บริษัทจัดเตรียมไว้ พร้อมทำ Workshop ร่วมกันกับวิทยากร
หมายเหตุ: - ผู้อบรมต้องนำเครื่องส่วนตัวมาใช้อบรมด้วยตัวเอง
- วันอบรมที่ชัดเจนทางบริษัทจะแจ้งภายหลัง ตามเดือนที่ผู้อบรมแจ้งความประสงค์ไว้ (ทางบริษัทขอสงวนสิทธิ์การปรับเปลี่ยน ตามความเหมาะสม)
In-house Training หมายถึง การอบรมให้กับบริษัทของลูกค้าโดยตรง โดยใช้สถานที่ของลูกค้าที่จัดเตรียมไว้ หรือจะเป็นแบบ Online ก็ได้เช่นกัน และลูกค้าสามารถเลือกวันอบรมได้
ลงทะเบียนอบรมได้ที่
เน้นการทำ Workshop ที่ถูกออกแบบมาอย่างดีเยี่ยม, สนุกสนาน, ครบครัน เพื่อช่วยในการเรียนรู้และทำให้เกิดความเข้าใจได้อย่างง่ายดายที่สุด
#พร้อมเอกสาร lab #ทุกขั้นตอน
(ลิขสิทธิ์ โดย อ.สุรัตน์ เกษมบุญศิริ)
เนื้อหาต่างๆ มีการปรับเปลี่ยน/จัดหมวดหมู่ ใหม่ทั้งหมด เพื่อทำให้ง่ายต่อความเข้าใจ
การันตีครับ ว่า ผู้อบรมทุกคนที่จบจาก course นี้จะได้รับความรู้ทั้งภาคทฤษฏีและภาคปฏิบัติ อย่างครบถ้วน เพื่อนำไปใช้ในการทำงานจริง
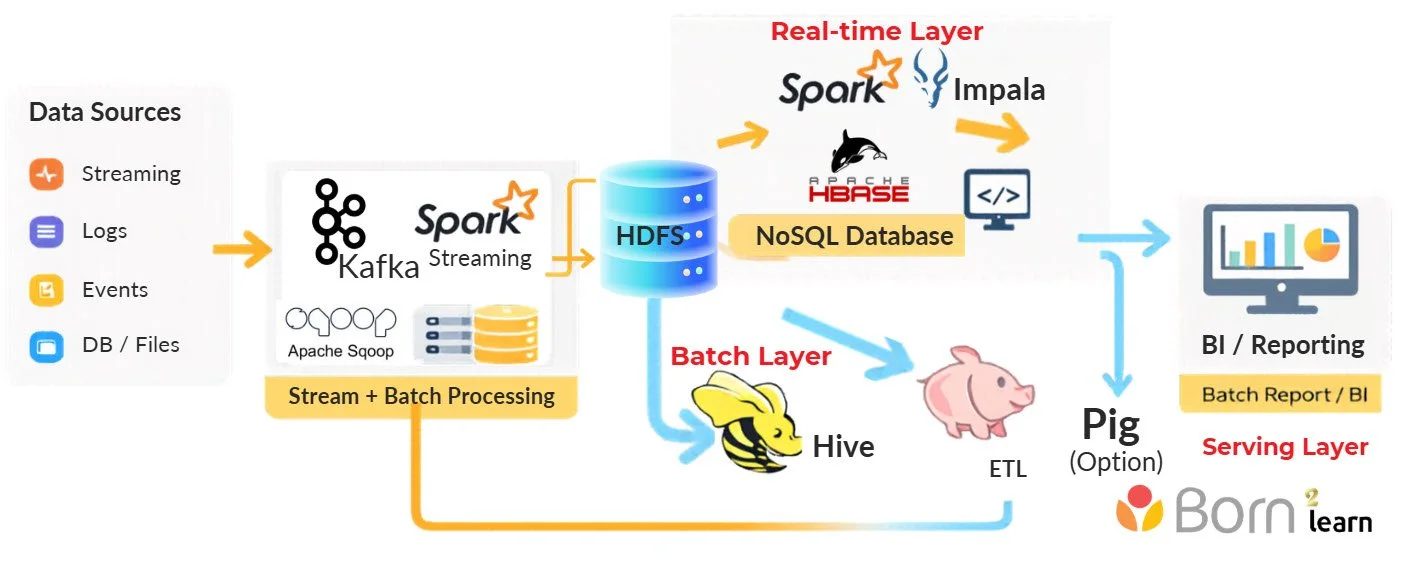
📌เริ่มปูตั้งแต่พื้นฐาน Big Data และ Hadoop Ecosystem สำหรับการใช้งานจริงในองค์กร
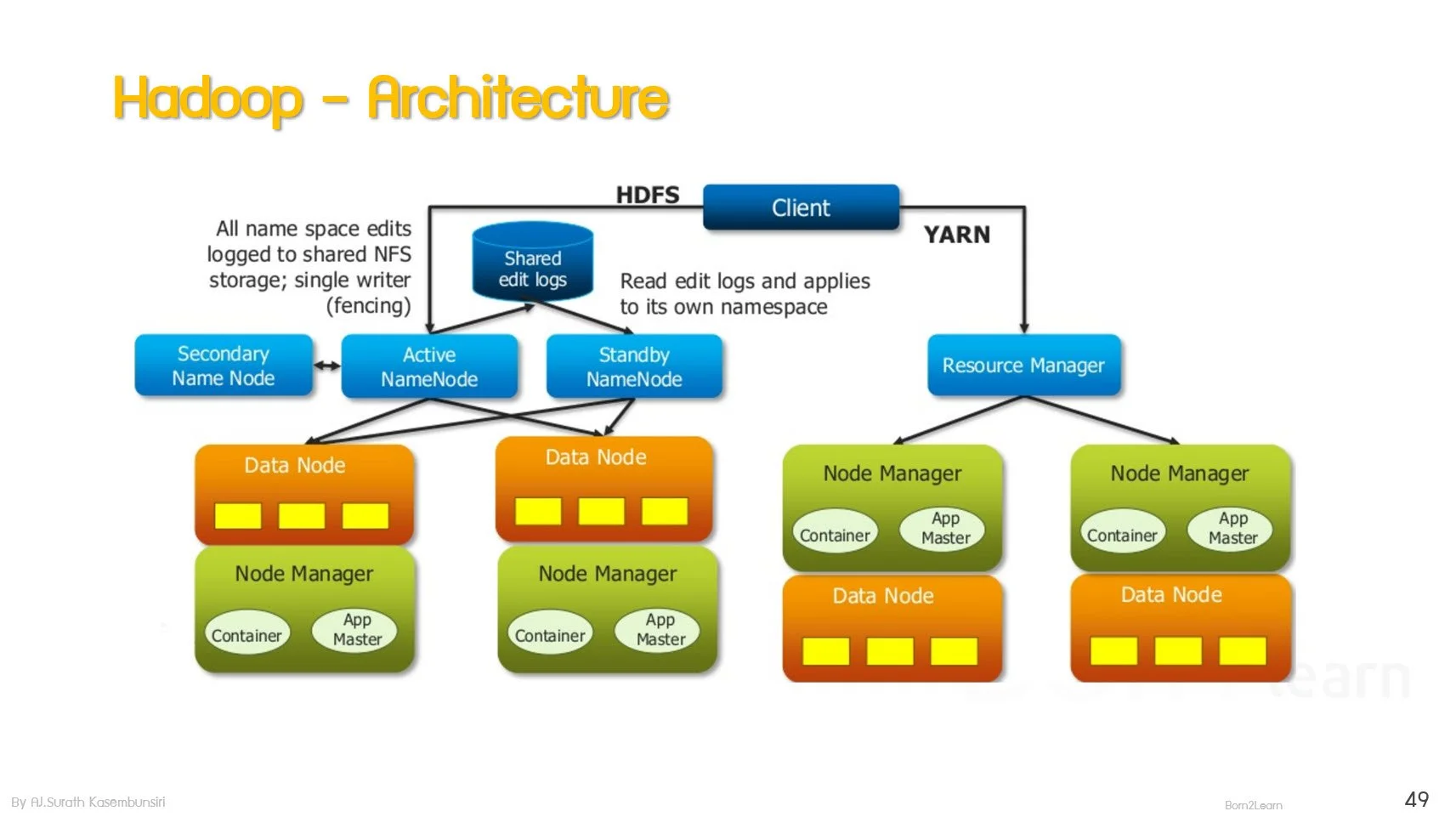
📌เข้าใจภาพรวมของ Hadoop Architecture และการทำงานของแต่ละ Component เช่น HDFS, YARN และ MapReduce
📌 สามารถออกแบบและติดตั้ง Hadoop Environment ได้อย่างเหมาะสม ทั้งแบบ Standalone และ Cluster
📌 เข้าใจการทำงานของ HDFS อย่างลึกซึ้ง ทั้ง Storage, Replication และ High Availability
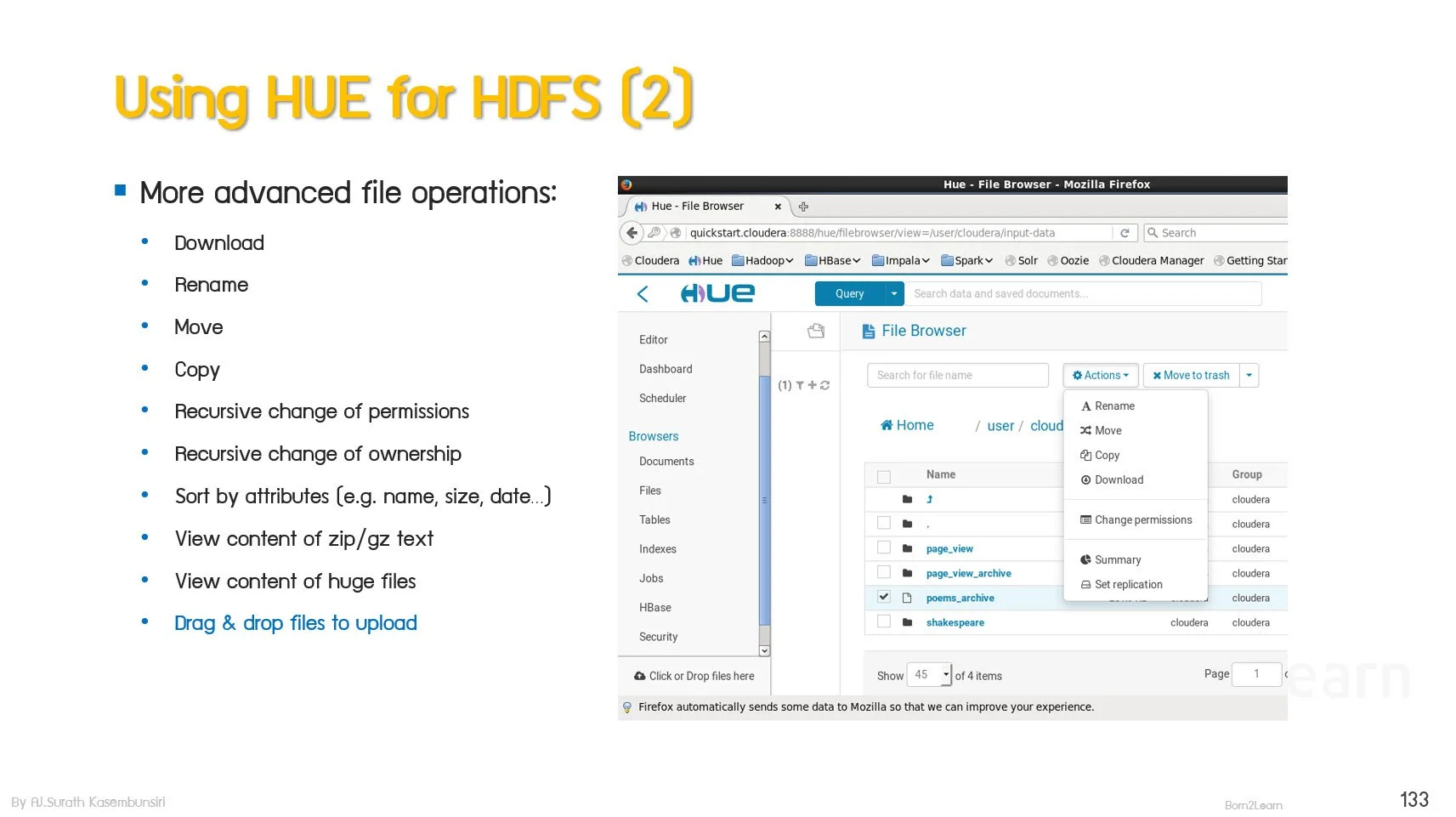
📌 สามารถใช้งาน HDFS ผ่าน Shell Command และเครื่องมืออย่าง Hue ได้อย่างถูกต้อง
📌 เข้าใจแนวคิดการประมวลผลแบบ Batch ด้วย MapReduce และลำดับการทำงานจริงในระบบ
📌 สามารถใช้ Hive ในการ Query ข้อมูลขนาดใหญ่ด้วย SQL (HiveQL) ได้อย่างมีประสิทธิภาพ
📌 เข้าใจการออกแบบและใช้งาน Internal และ External Tables ใน Hive สำหรับงานจริง
📌 เข้าใจการใช้ Impala สำหรับการ Query แบบ Real-time และเลือกใช้ให้เหมาะกับ Use Case
📌 สามารถใช้ Pig ในการทำ ETL และ Data Pipeline สำหรับการเตรียมข้อมูลได้อย่างเหมาะสม
📌 สามารถใช้ Spark ในการประมวลผลข้อมูลทั้งแบบ Batch และ Streaming ได้อย่างมีประสิทธิภาพ
📌 เข้าใจโครงสร้างและการใช้งาน HBase สำหรับงานที่ต้องการ Real-time Data Access
📌 สามารถทำ Data Integration ระหว่าง RDBMS และ Hadoop ด้วย Sqoop ได้อย่างถูกต้อง
📌 เข้าใจการทำ Incremental Import และการจัดการข้อมูลขนาดใหญ่แบบ Parallel
📌 สามารถออกแบบและพัฒนา Real-time Data Processing ด้วย Spark Streaming ได้
📌 เข้าใจภาพรวมของ Lambda Architecture และการออกแบบ Data Pipeline แบบ End-to-End
📌 Workshop ตลอดการฝึกอบรม โดย lab practice ที่มีคุณภาพและทำให้กลมกล่อม เข้าใจง่าย โดย อ.สุรัตน์
📌 เหมาะสำหรับองค์กรที่ต้องการเริ่มต้น Big Data อย่างถูกต้องและใช้งานได้จริง
📌 มาร่วมเรียนรู้การ implement และบริหารจัดการระบบ Big Data ด้วย Hadoop แบบมืออาชีพ กับ Born2Learn

วิทยากร:
อ.สุรัตน์ เกษมบุญศิริ
ผู้เชี่ยวชาญและวิทยากรที่มีประสบการณ์มากกว่า 20 ปีในวงการ
พร้อมด้วยใบรับรองจากบริษัทระดับโลกมากมาย อาทิเช่น Microsoft, CompTIA, ITIL, Cisco และอื่นๆ
หลักการและเหตุผล :
This course provides fundamental knowledge and practical skills for working with the Apache Hadoop ecosystem.
The course is designed for IT professionals who want to transition into Big Data and build real-world data processing solutions.
หลักสูตรนี้เหมาะสำหรับ:
· Developers who want to work with Big Data technologies
· Database Administrators interested in Hadoop ecosystem
· Data Engineers and Data Analysts working with large-scale data
· IT Professionals who want to build skills in Big Data platforms
· Beginners who want to start learning Hadoop and Data Lake concepts
วัตถุประสงค์ของหลักสูตร:
· Understand Big Data concepts and real-world use cases for modern data platforms
· Explain Hadoop ecosystem architecture and how each component works together
· Install and configure Apache Hadoop environment (Standalone and Cluster)
· Work with HDFS for data storage, replication, and high availability
· Understand and execute batch processing with MapReduce (concept & workflow)
· Query large-scale data using Hive and Impala (SQL-based analytics)
· Build data pipelines and ETL processes using Pig and Spark
· Process data using Apache Spark (Batch and Streaming workloads)
· Design and use HBase for real-time data access (NoSQL)
· Transfer data between RDBMS and Hadoop using Sqoop (including incremental load)
· Design end-to-end Big Data pipeline (Batch + Real-time integration)
ความรู้พื้นฐาน
· Basic knowledge of SQL
· Understanding of relational database concepts
· Basic experience with database design
· Basic knowledge of Linux command line
· Fundamental understanding of data processing concepts
เนื้อหาหลักสูตร :
Module 1: Introduction to Big Data & Hadoop Ecosystem
· Understanding Big Data Fundamentals
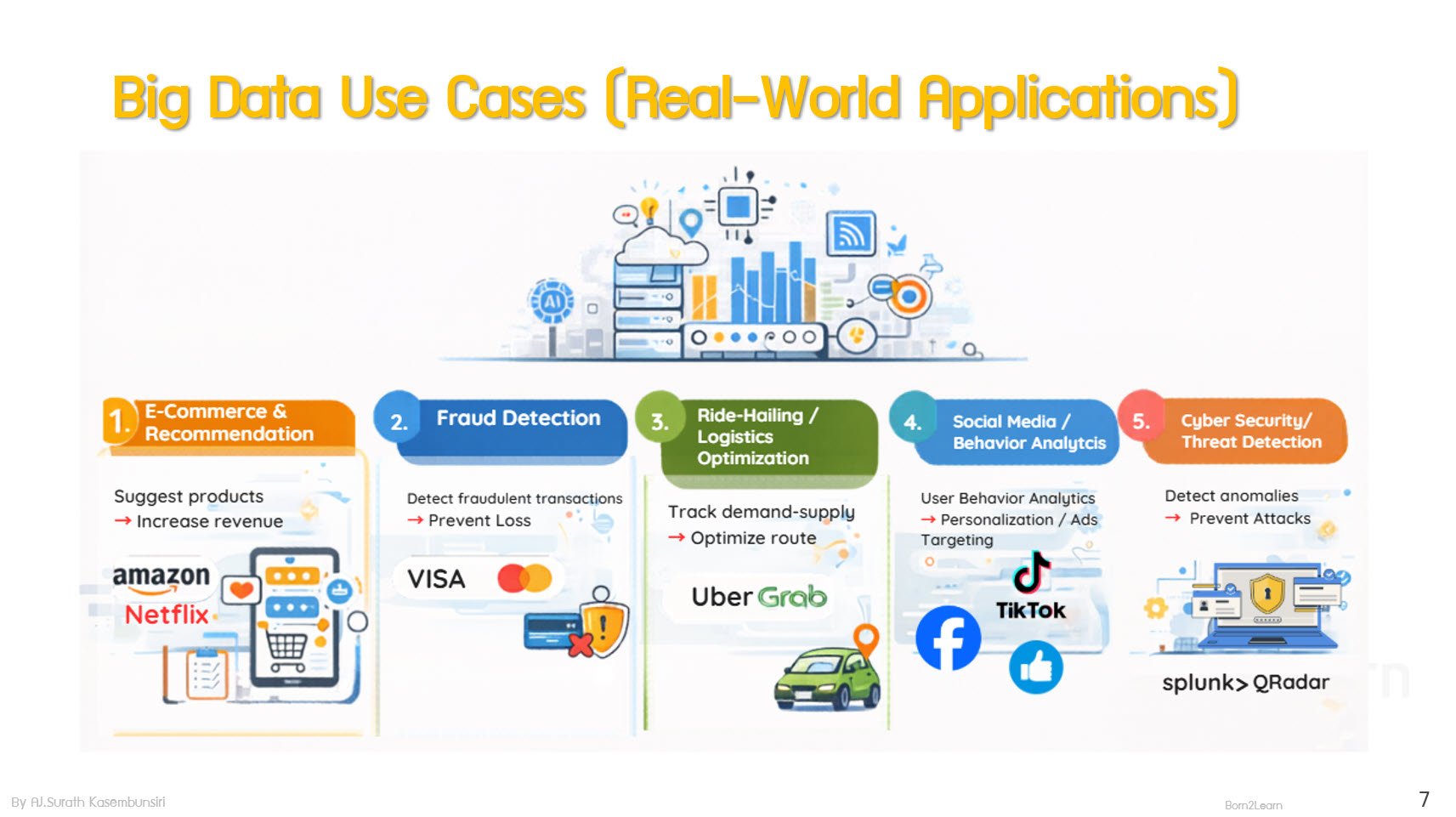
· Big Data Use Cases in Modern Systems
· Traditional RDBMS vs Big Data Technologies
· Introduction to Hadoop Ecosystem
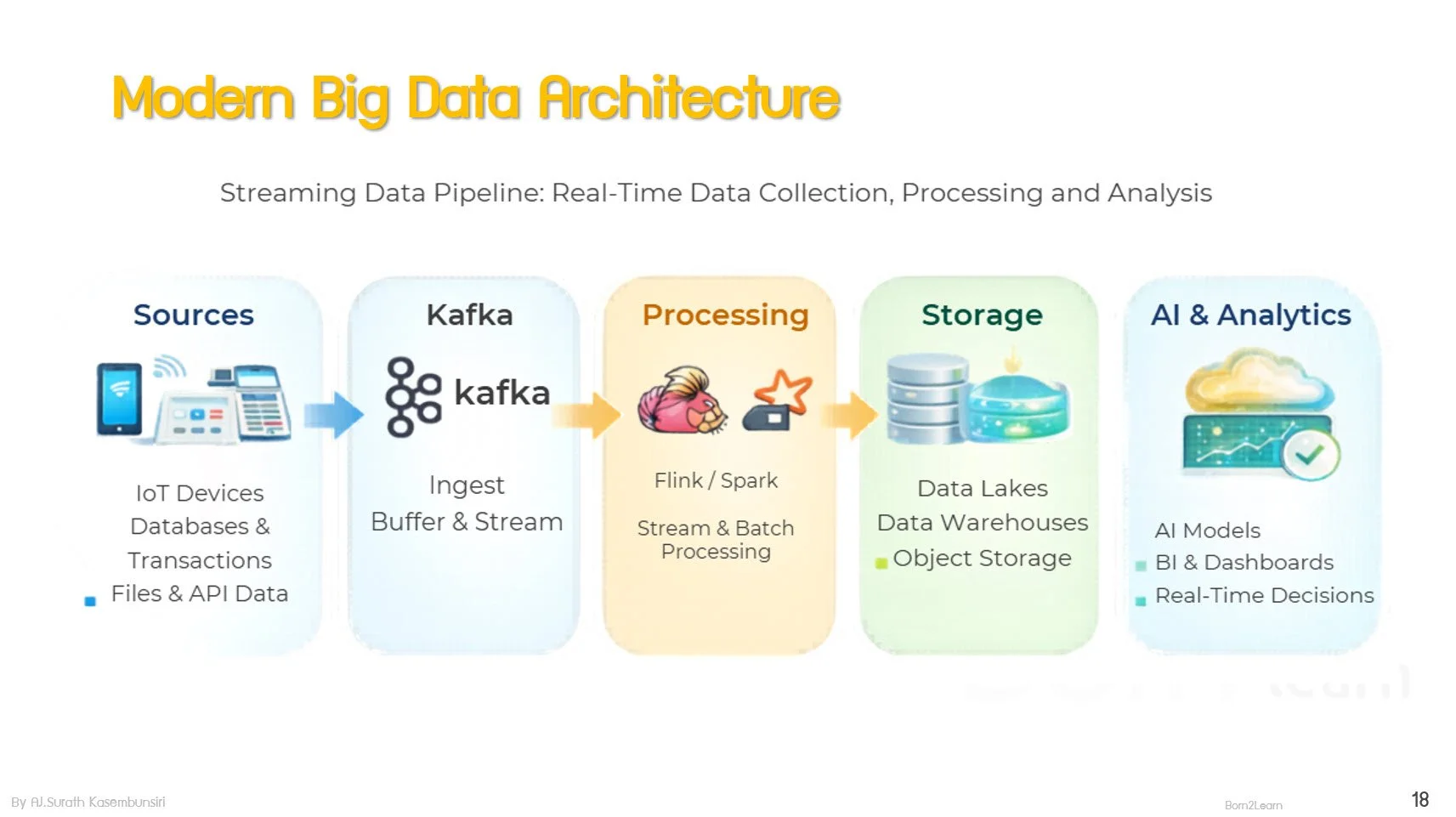
· Big Data Architecture & Implementation Concepts
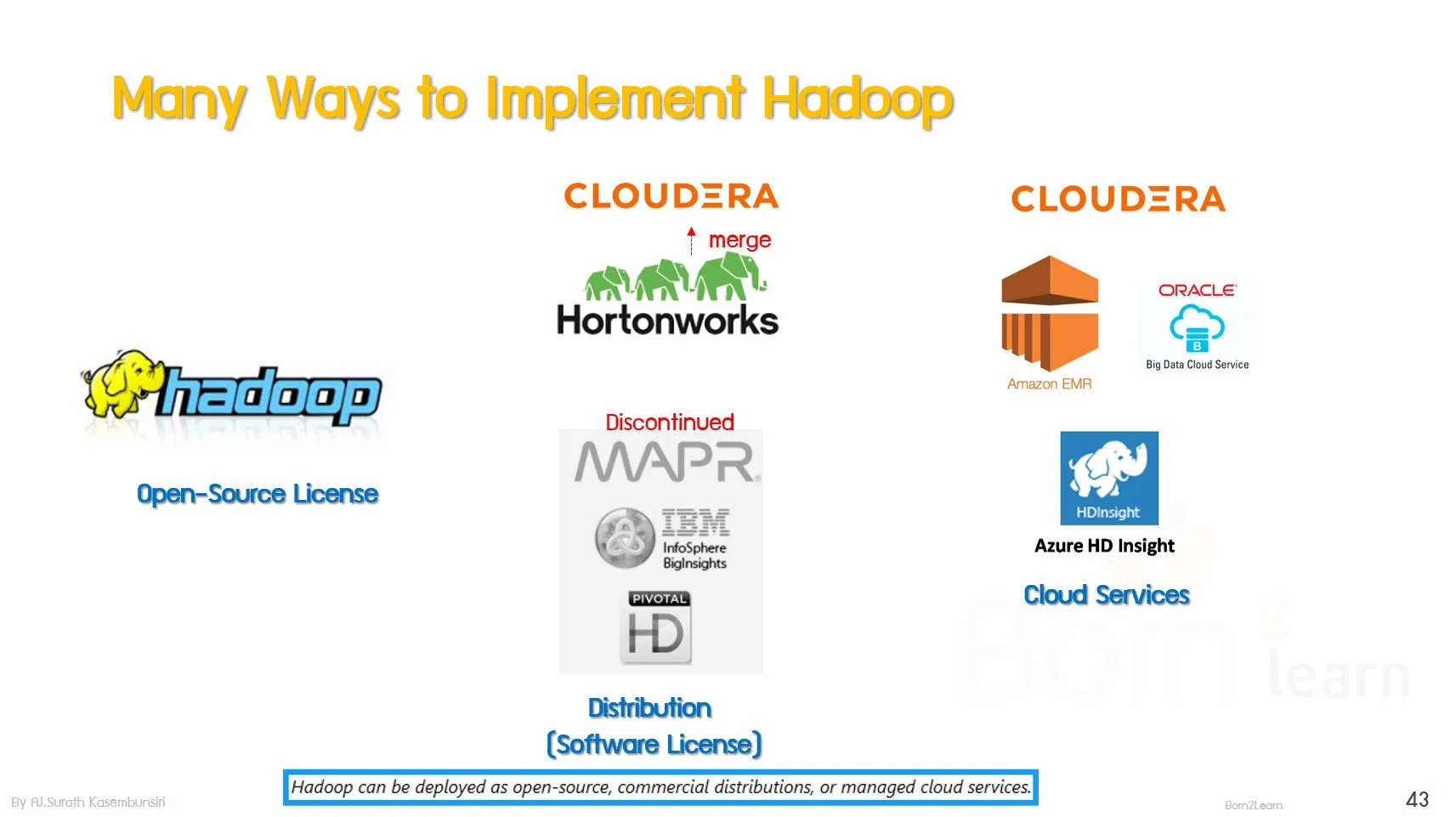
· Hadoop Distributions Comparison
· Data Lake Fundamentals
Module 2: Hadoop Fundamentals & Architecture
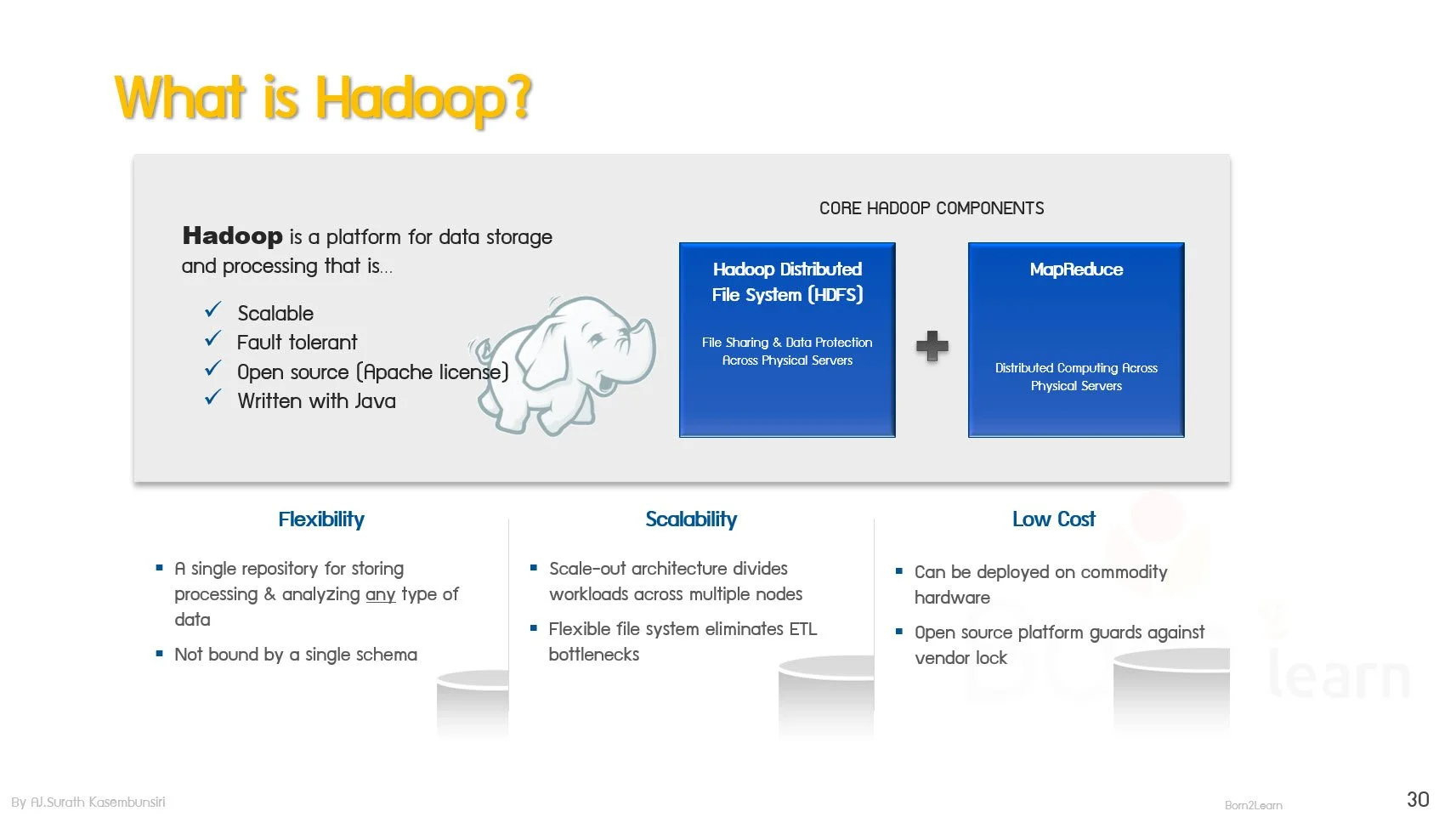
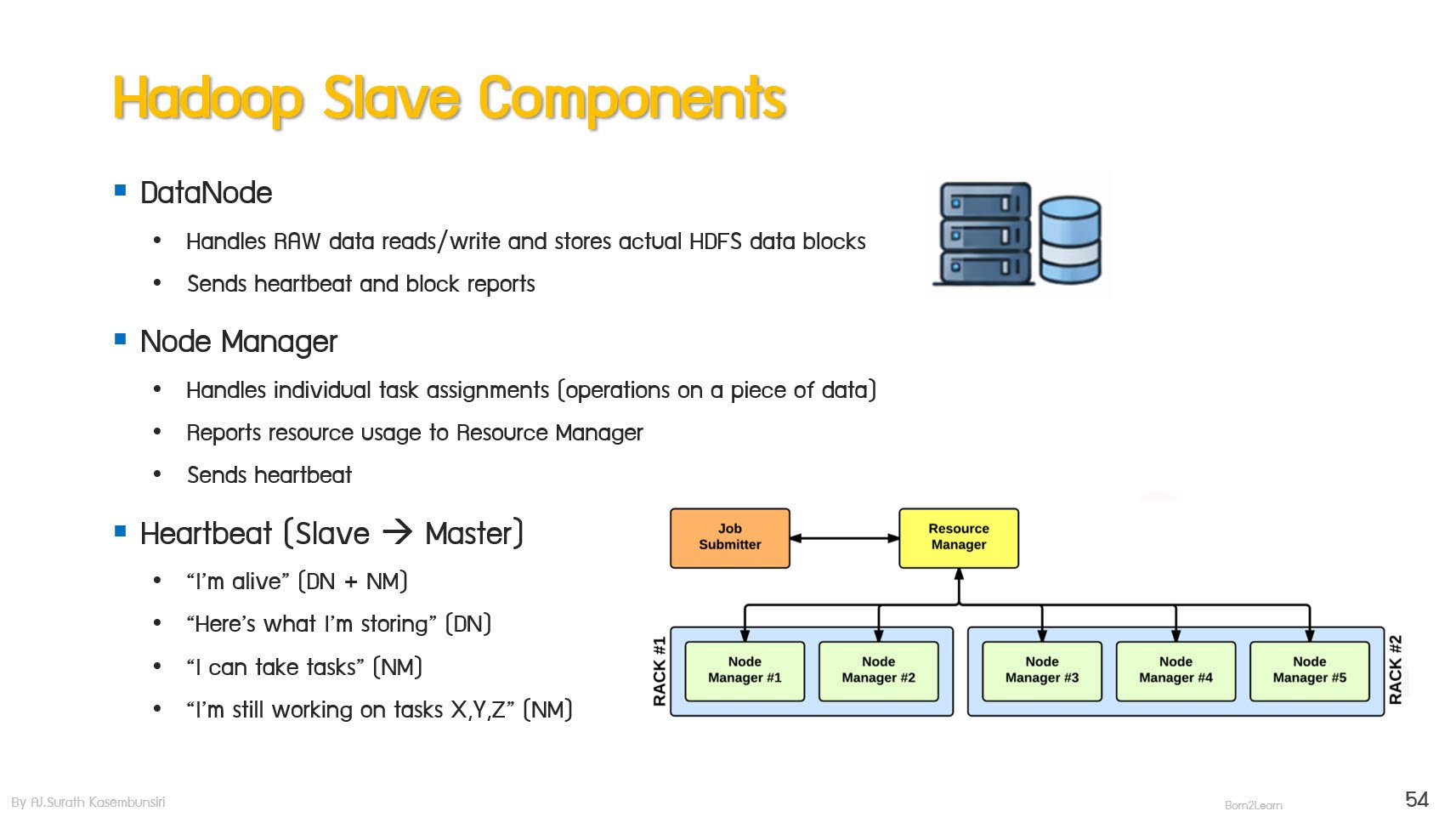
· Hadoop Core Components Overview
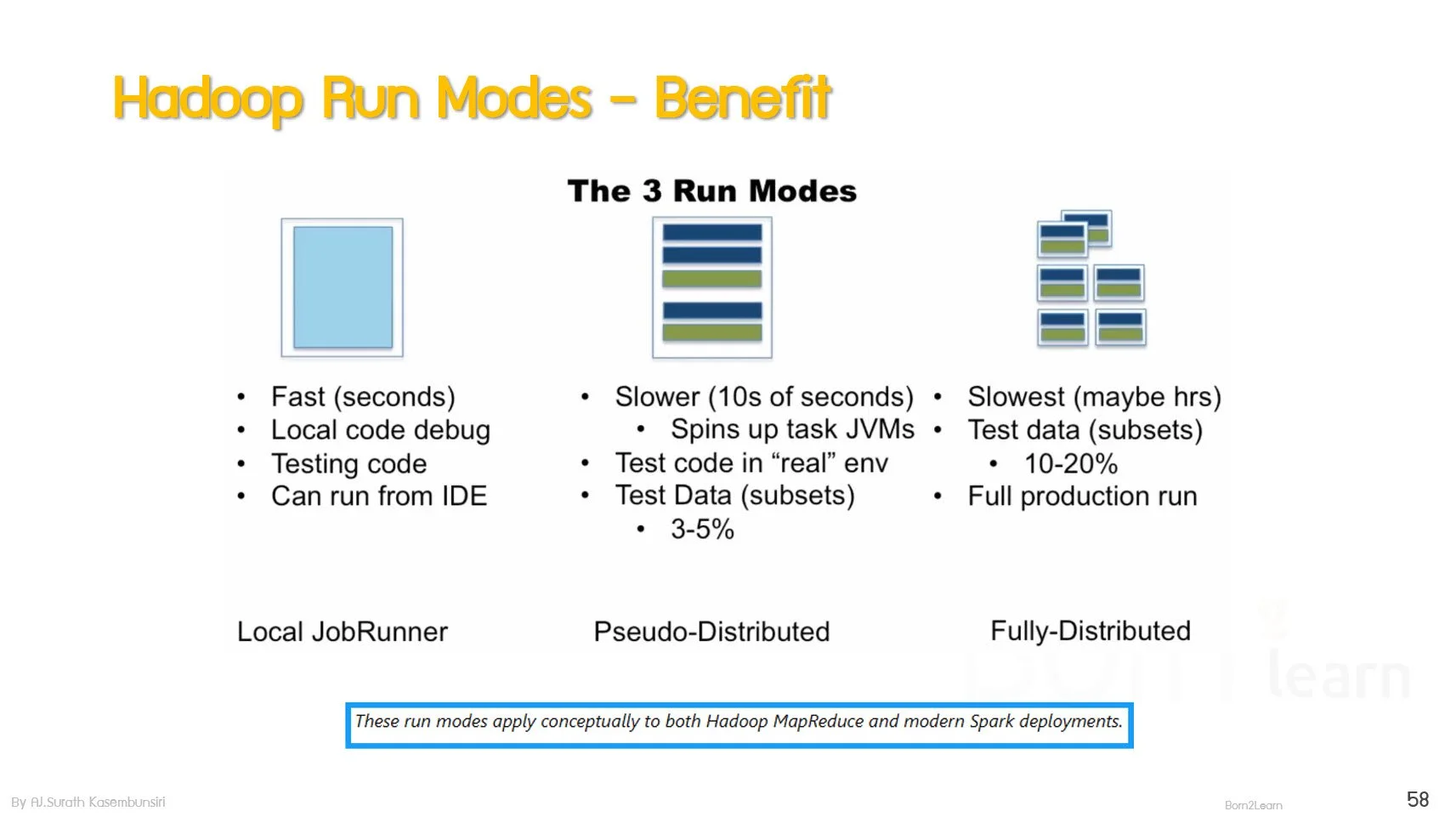
· Hadoop Run Modes
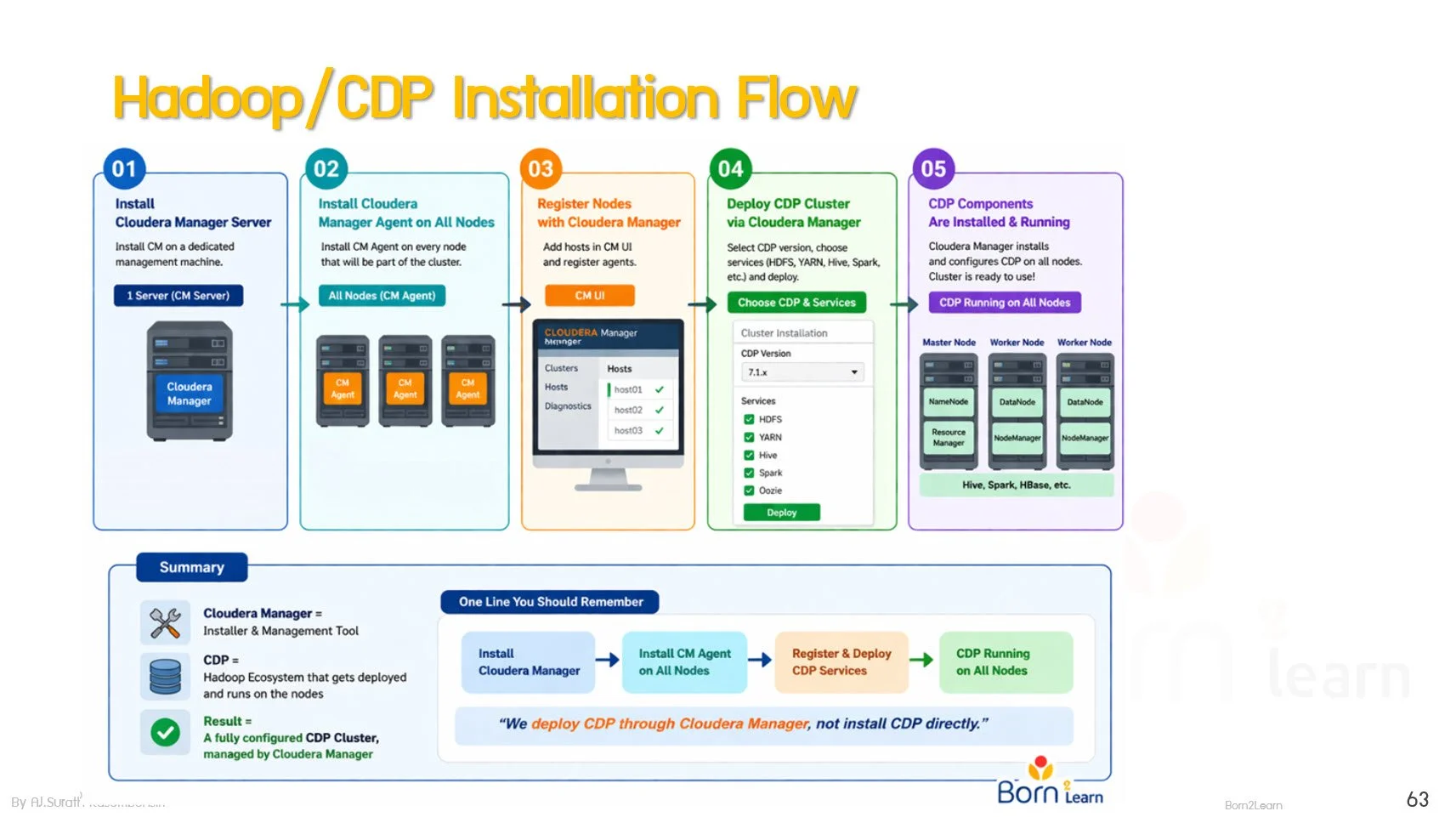
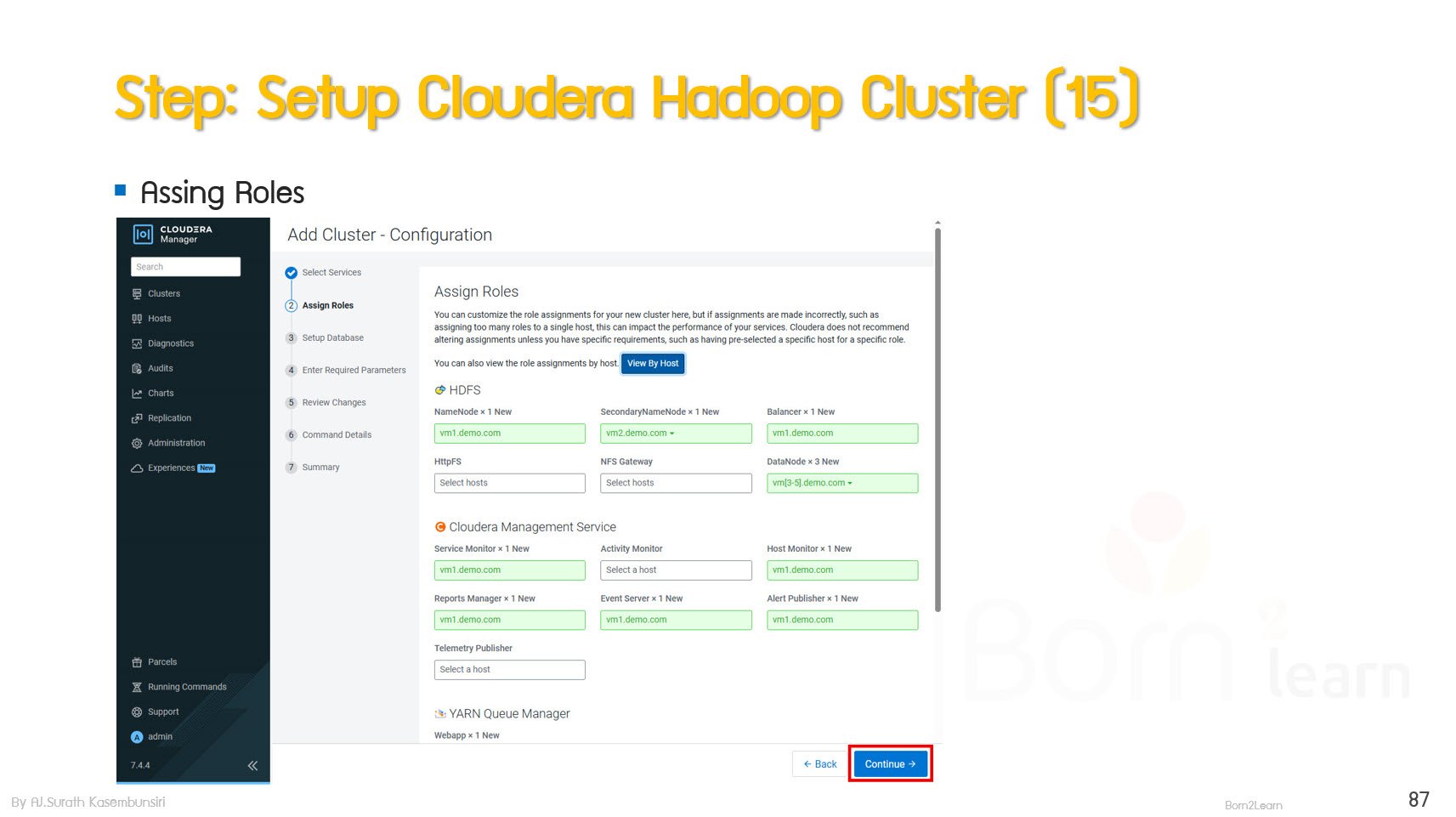
· Hadoop Installation & Environment Setup
· Cluster Management Tools Overview
· Introduction to Hue
Module 3: Distributed Storage with HDFS
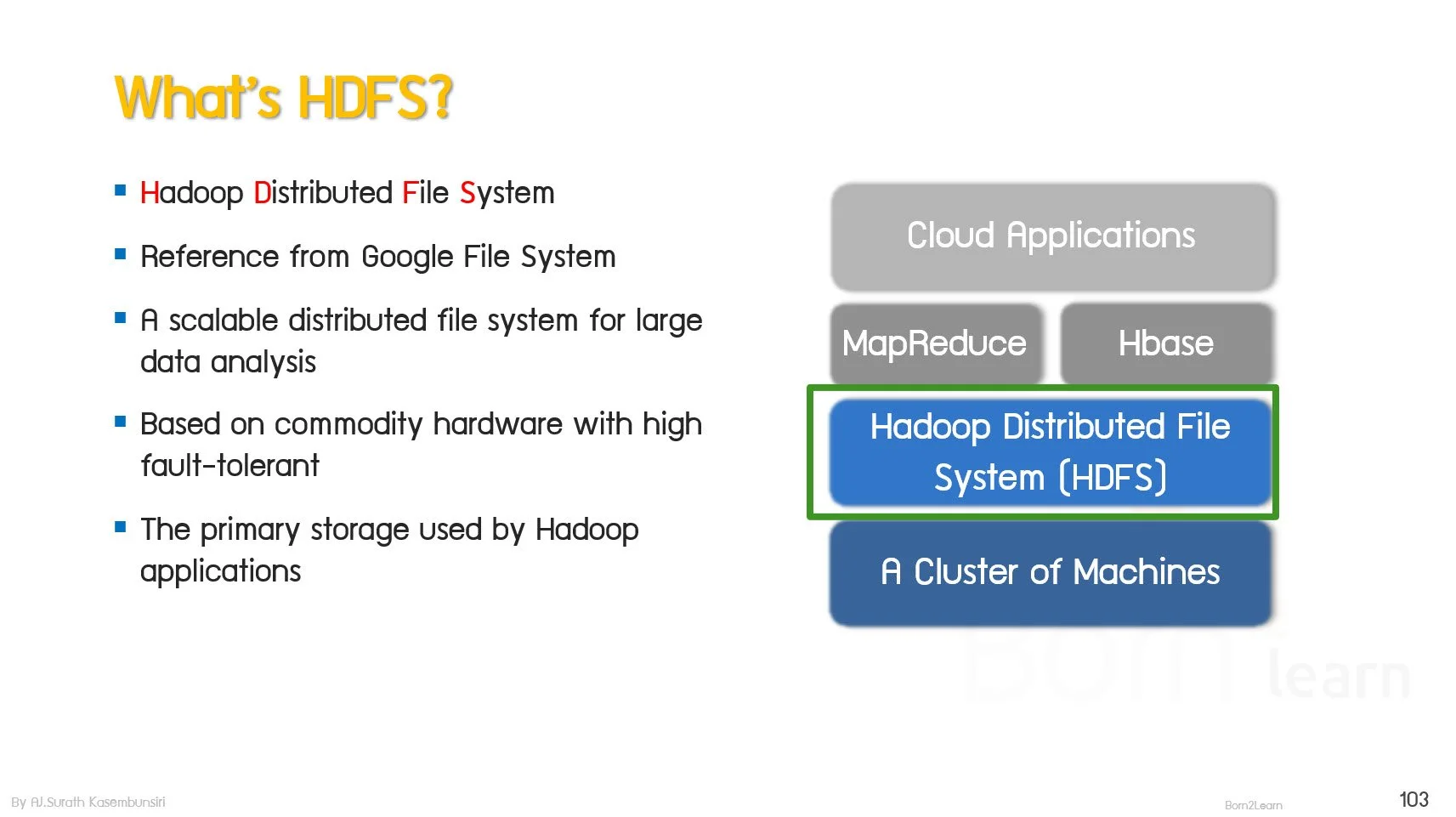
· HDFS Overview
· HDFS Core Concepts
· HDFS Architecture
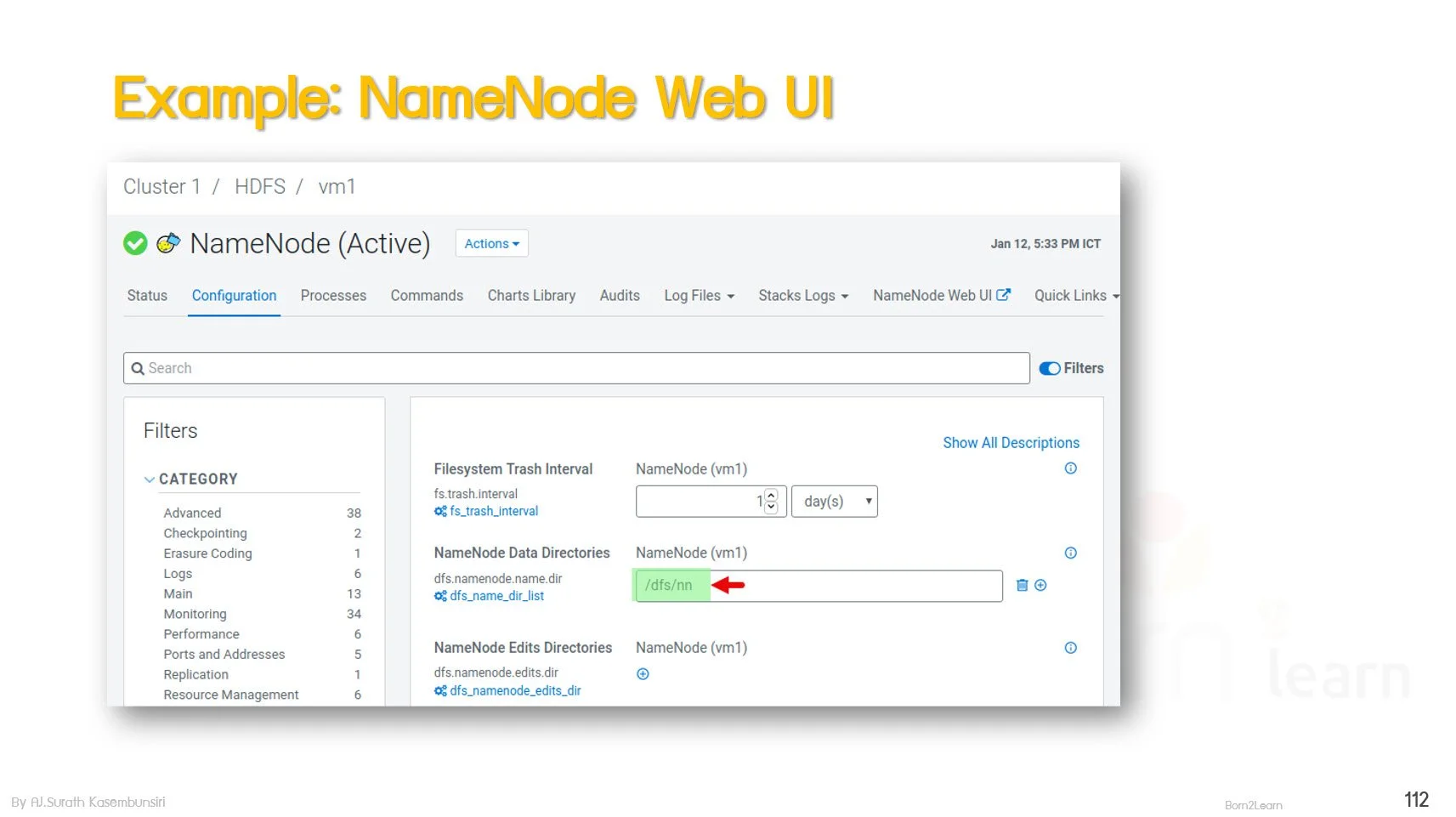
· HDFS Components: NameNode and DataNode
· NameNode Metadata Management
· Secondary NameNode Function
· HDFS High Availability Architecture
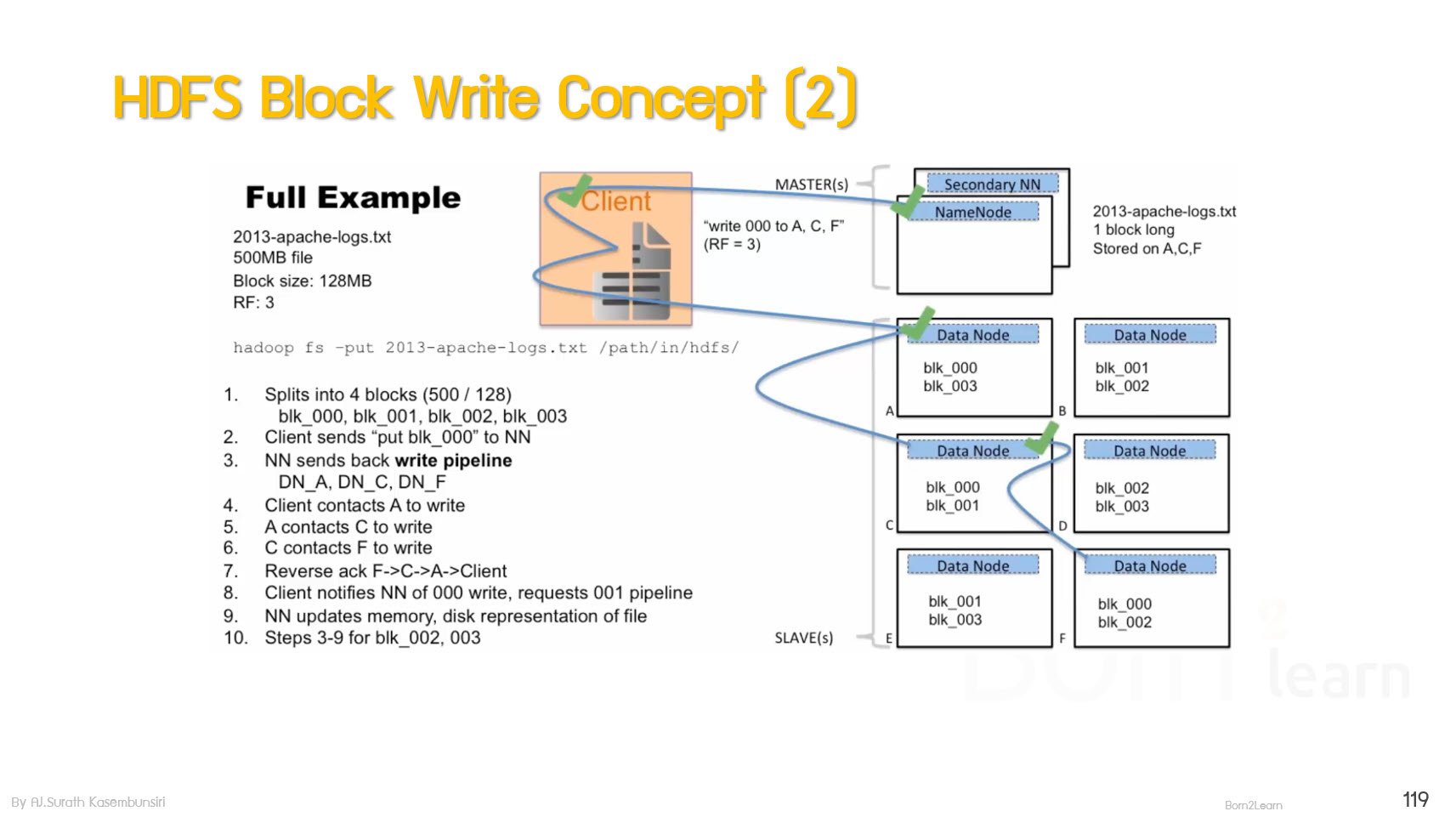
· HDFS Read and Write Workflow
· Managing HDFS with Shell Commands
· Managing HDFS with Hue
Module 4: Batch Processing with MapReduce
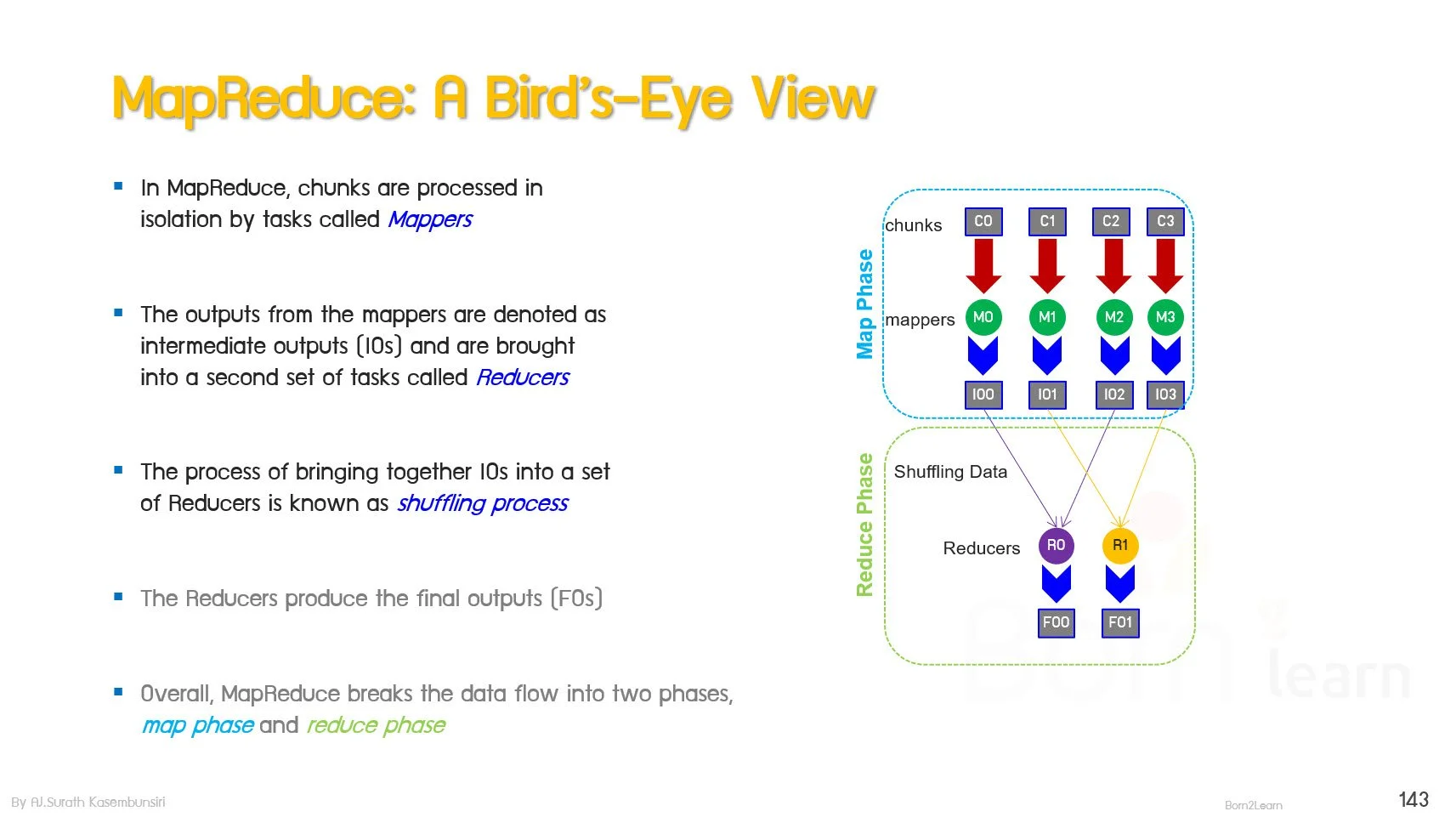
· MapReduce Overview
· Map Function Concept
· Reduce Function Concept
· Shuffle and Sort Phase
· MapReduce Execution Flow
· Input and Output Data Handling
· MapReduce Job Workflow
Module 5: Big Data Processing & Analytics Ecosystem
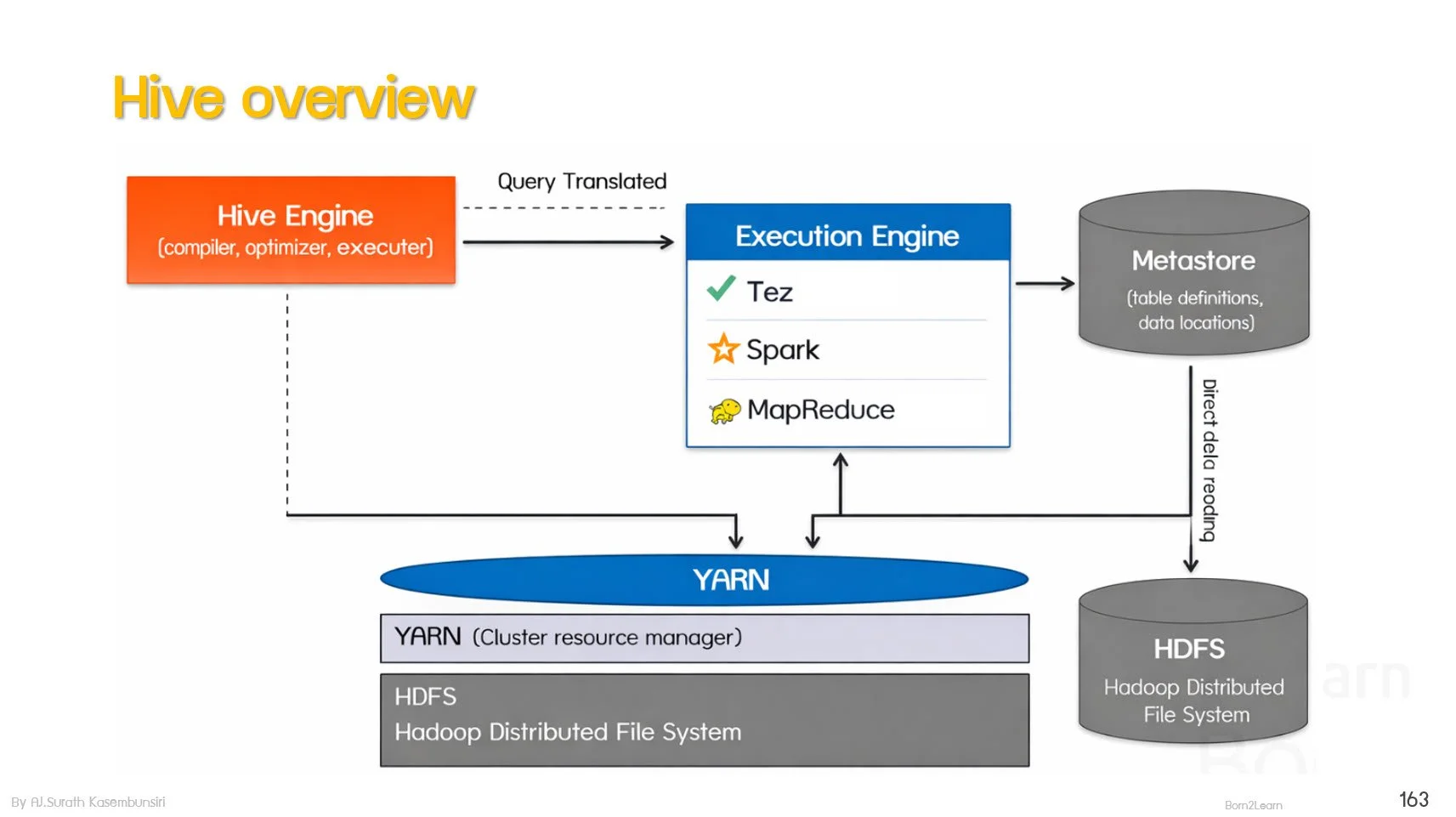
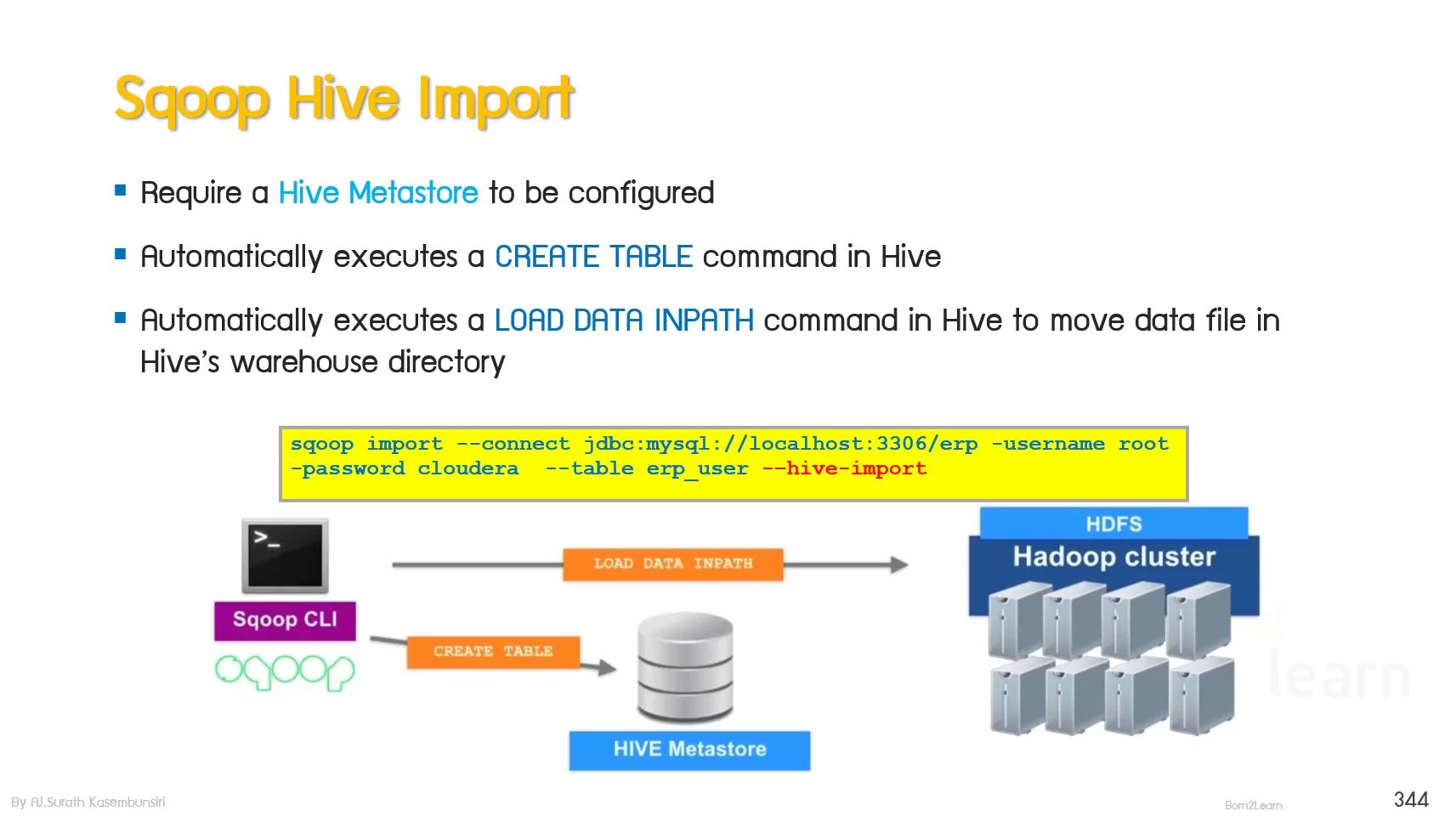
· Hive SQL-based batch processing on HDFS
Using HiveQL
Load Data to Hive’s Table
Internal / External Hive’s table
Query data with HiveQL
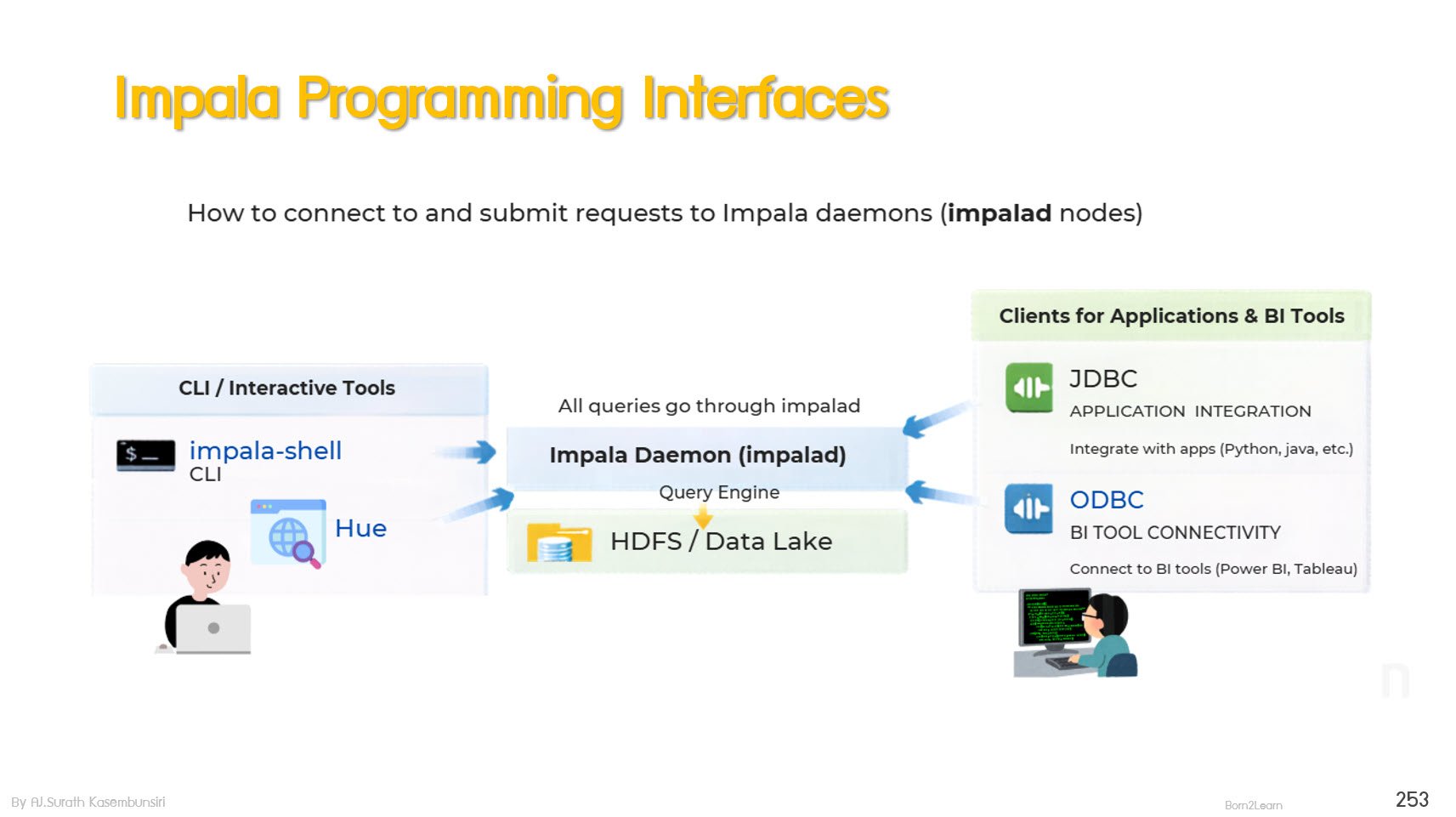
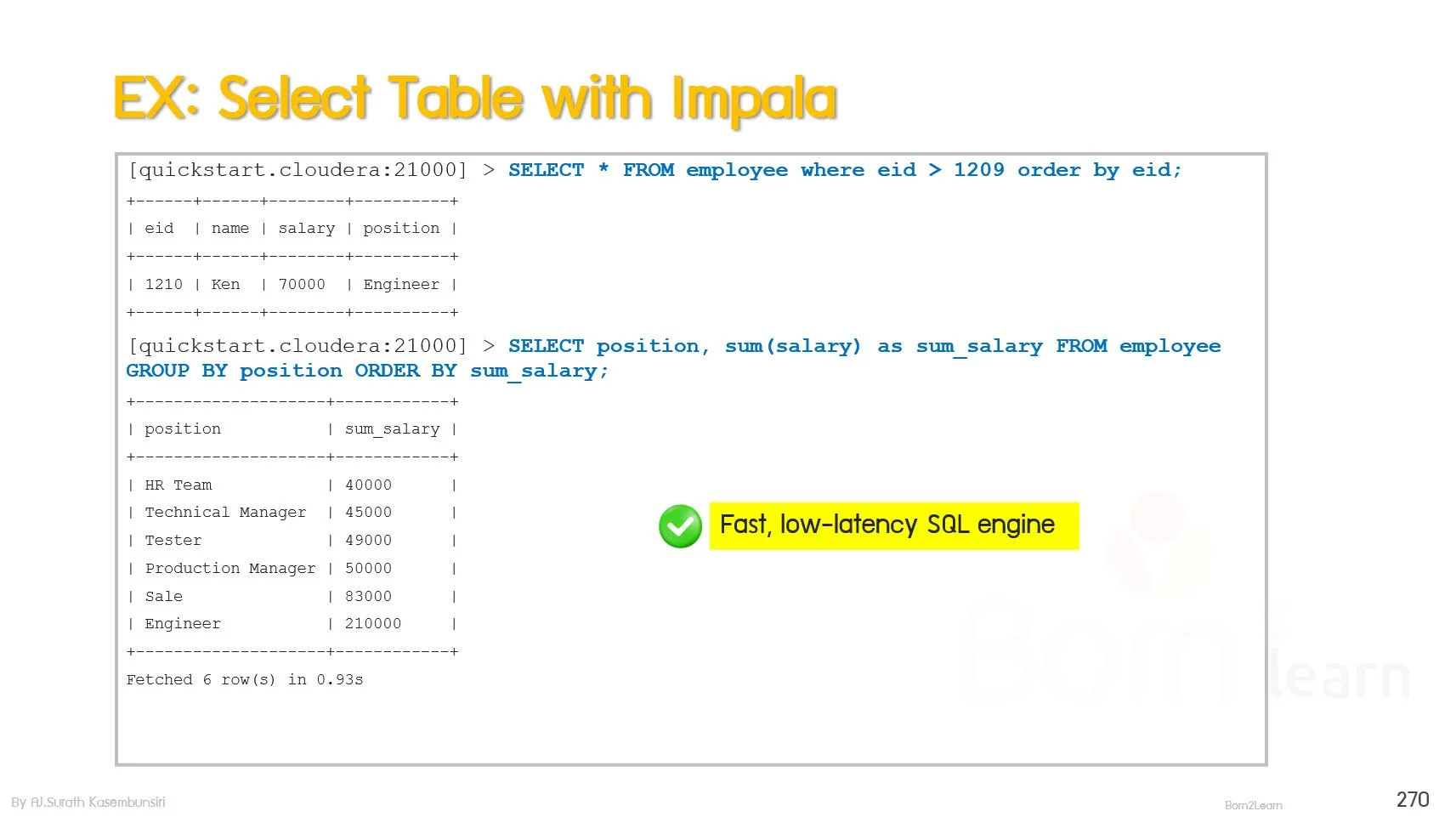
· Impala - Fast, low-latency SQL engine
Using Impala-shell
Load Data to Impala’s Table
Query data with Impala’s command
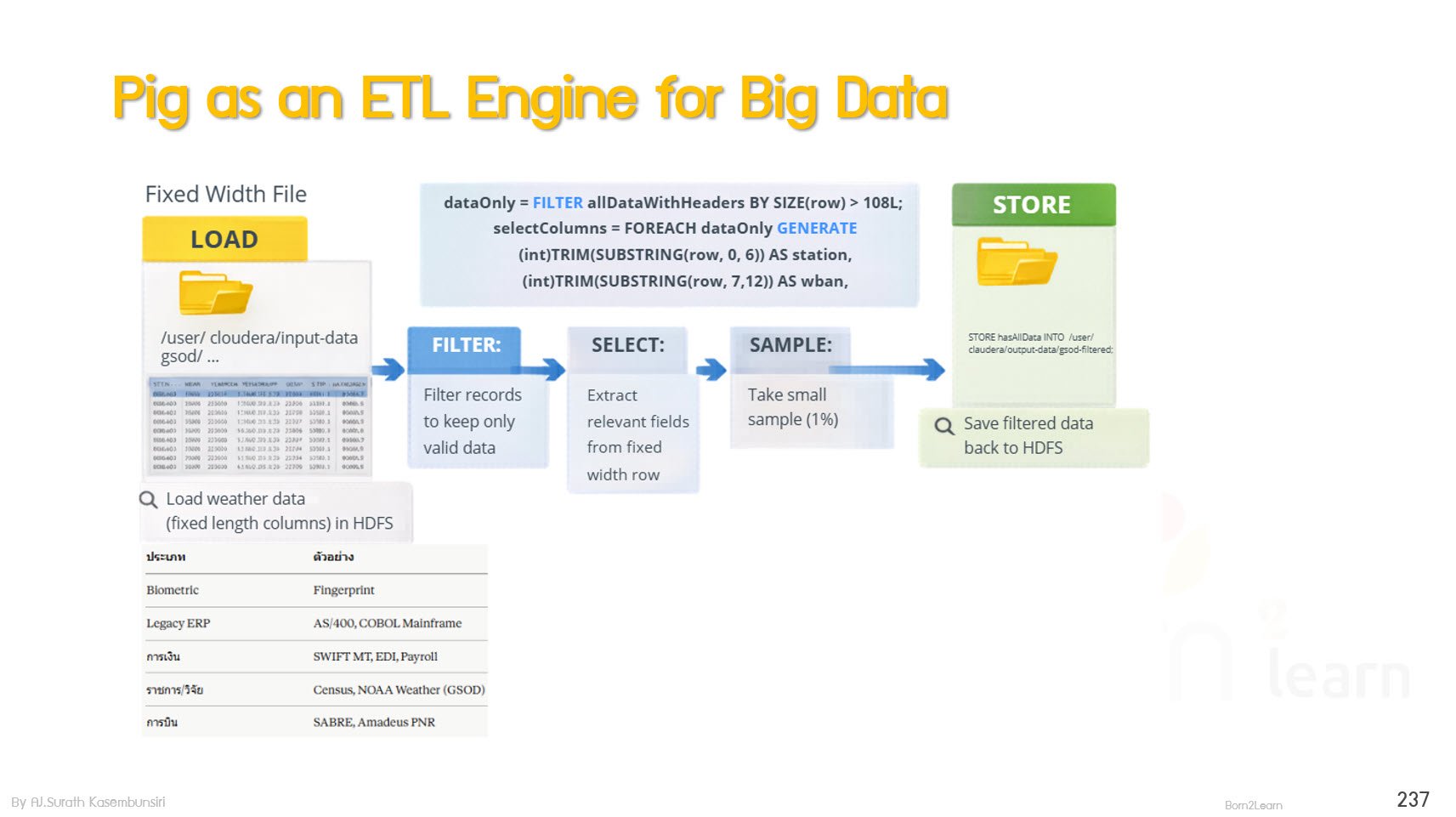
· Pig - Data pipeline development and ETL processing
Using Pig Latin
Data Model: Bags, Tuples, and Atoms
Data Transformation and Processing
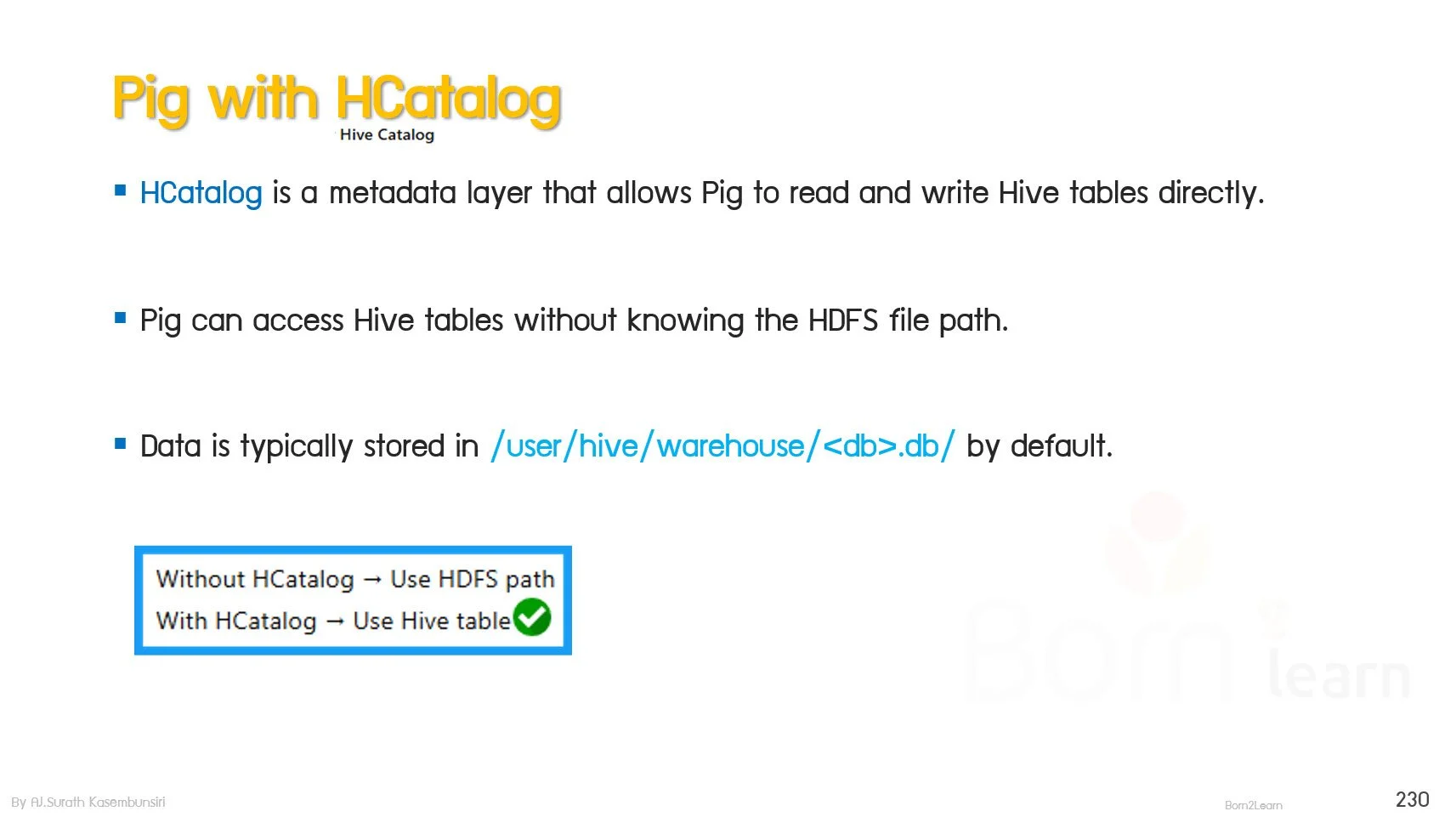
Integration with HCatalog
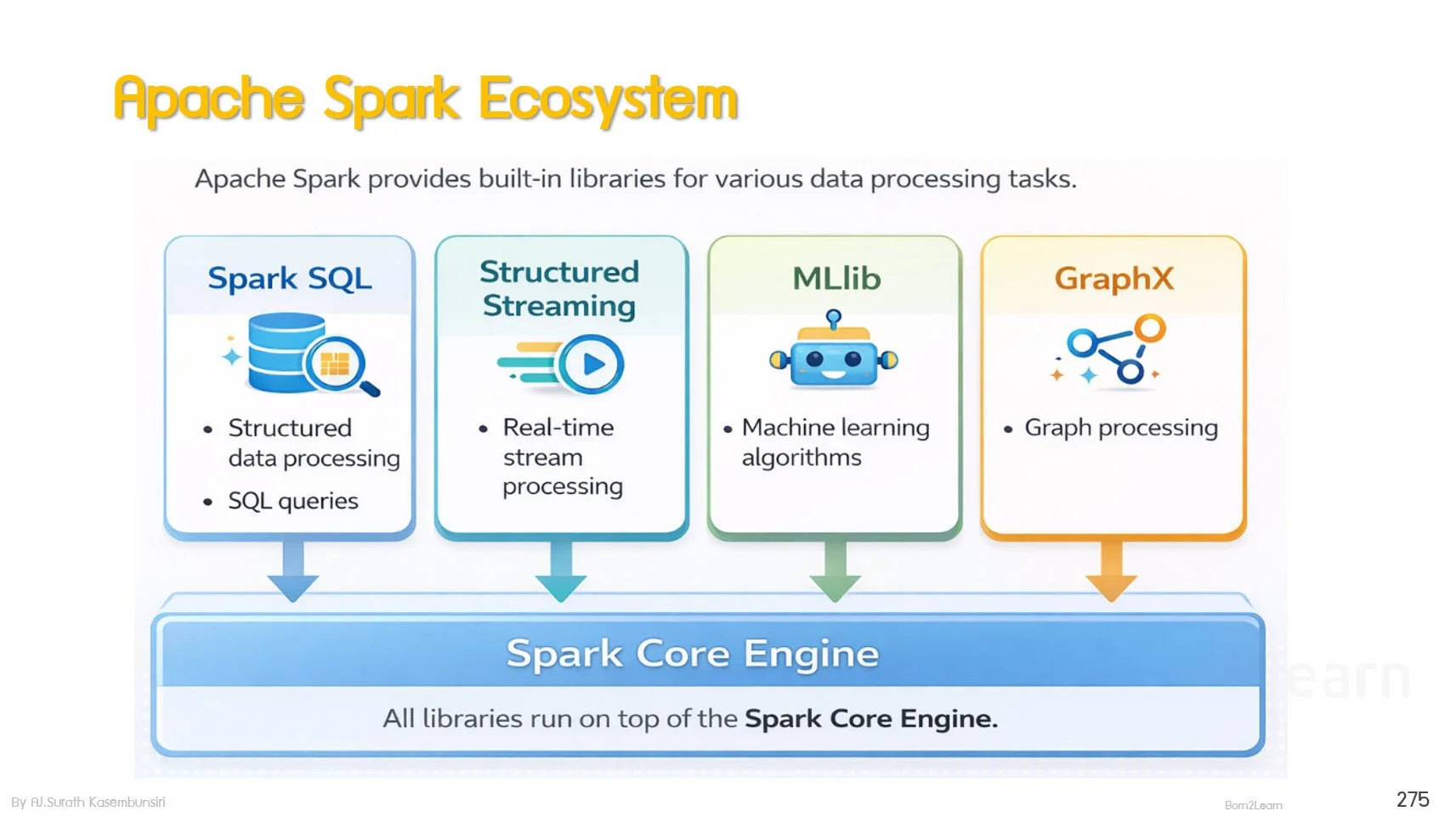
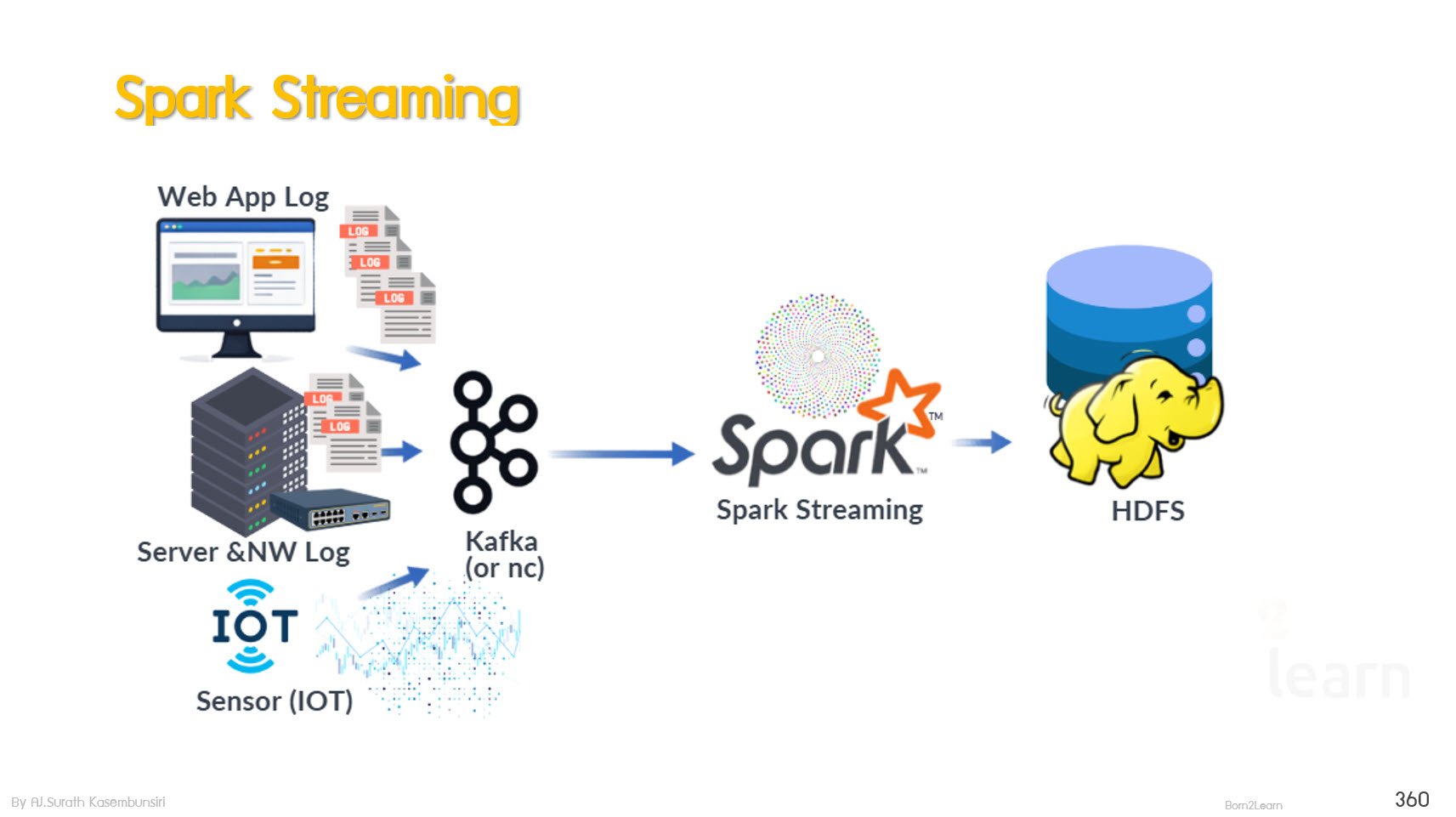
· Spark - Unified processing for batch and streaming workloads
Spark Architect and Ecosystem
RDD, Transformation and Actions
Spark Programming with HDFS
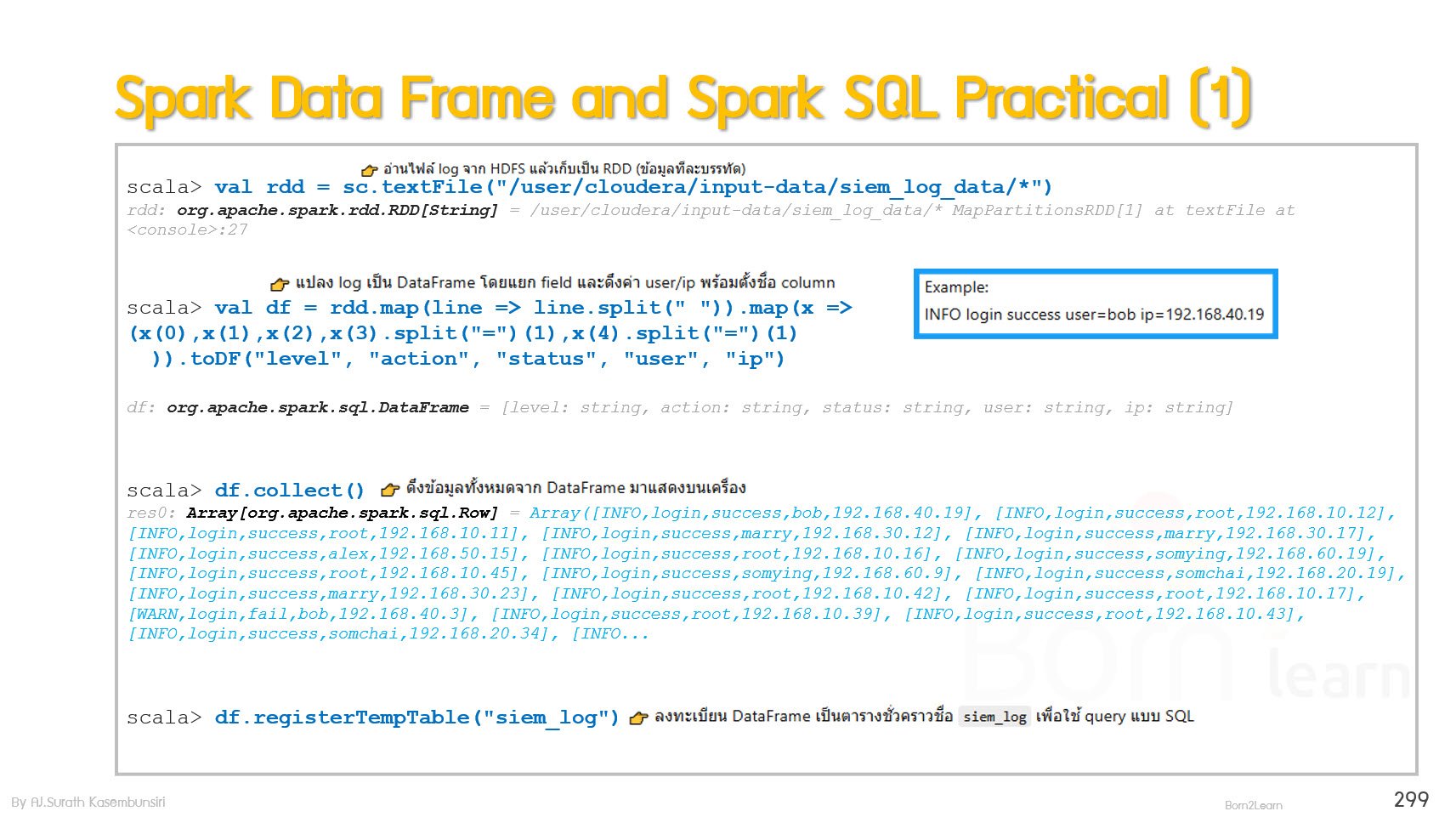
Spark Data Frame and Spark SQL
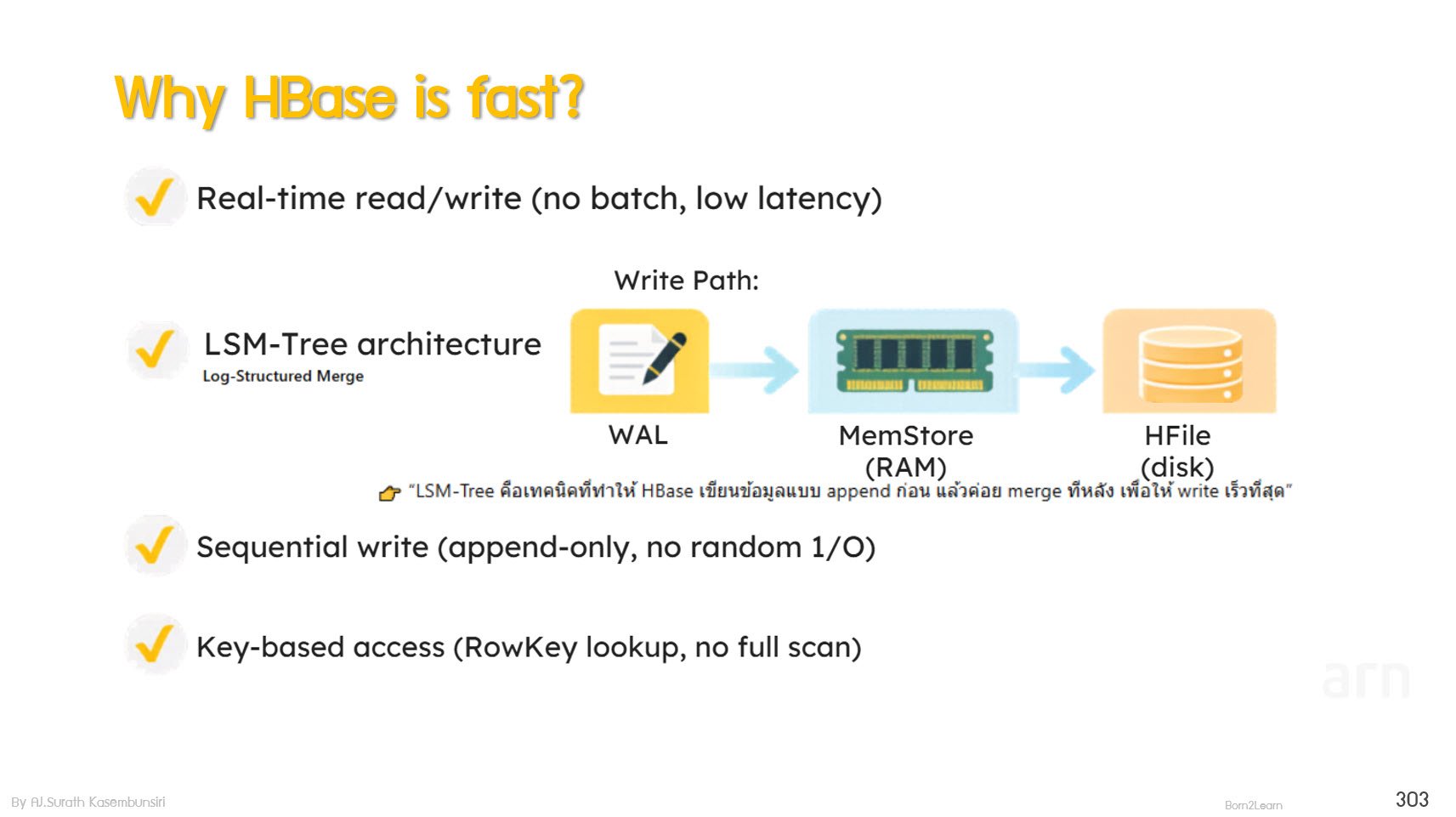
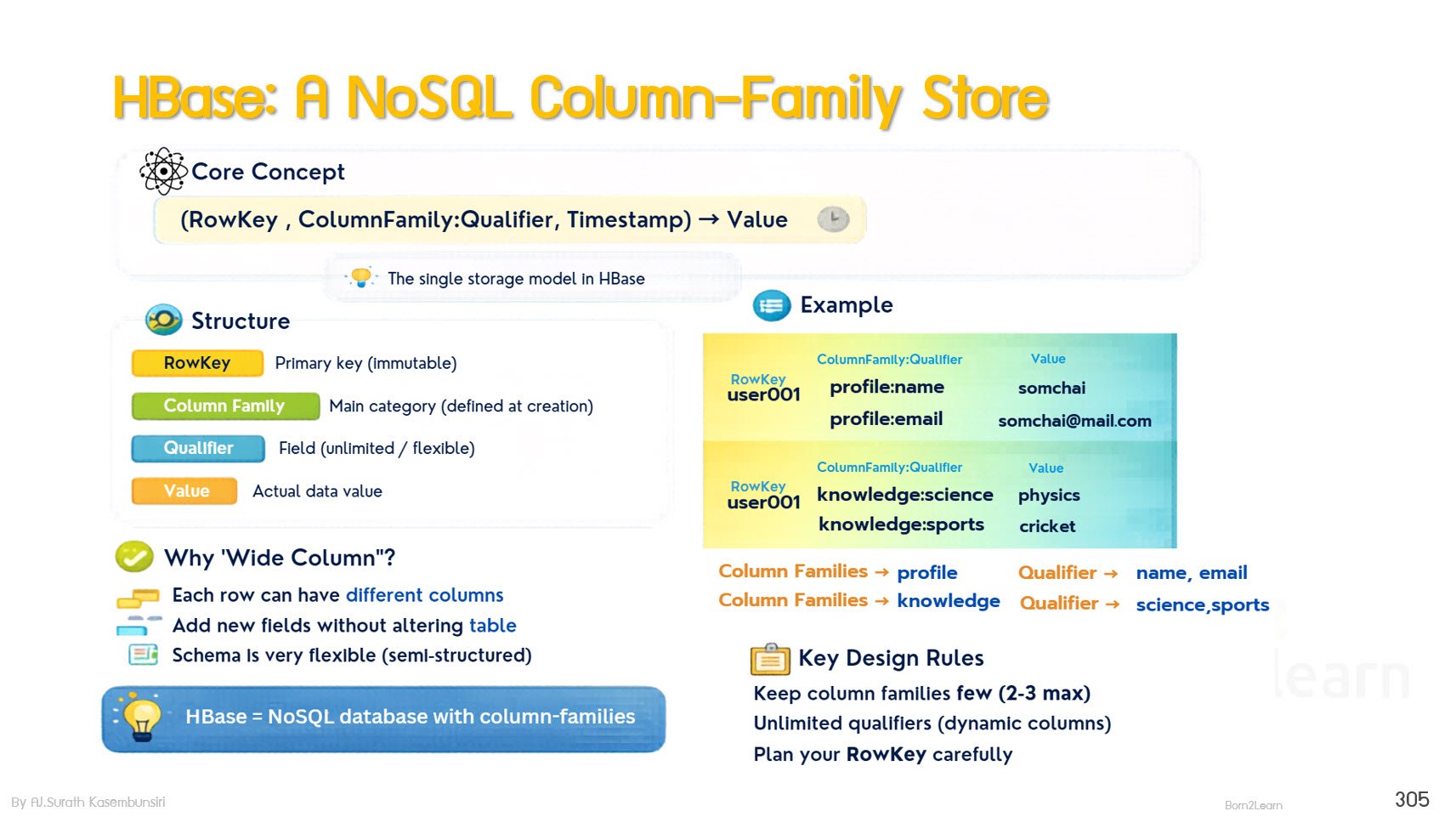
· HBase - Distributed NoSQL database for real-time access
HBase Architecture and Data Model
Column-Family Storage Concept
Read and Write Operations
Module 6: Data Integration & Real-Time Processing
· Lambda Architecture Overview
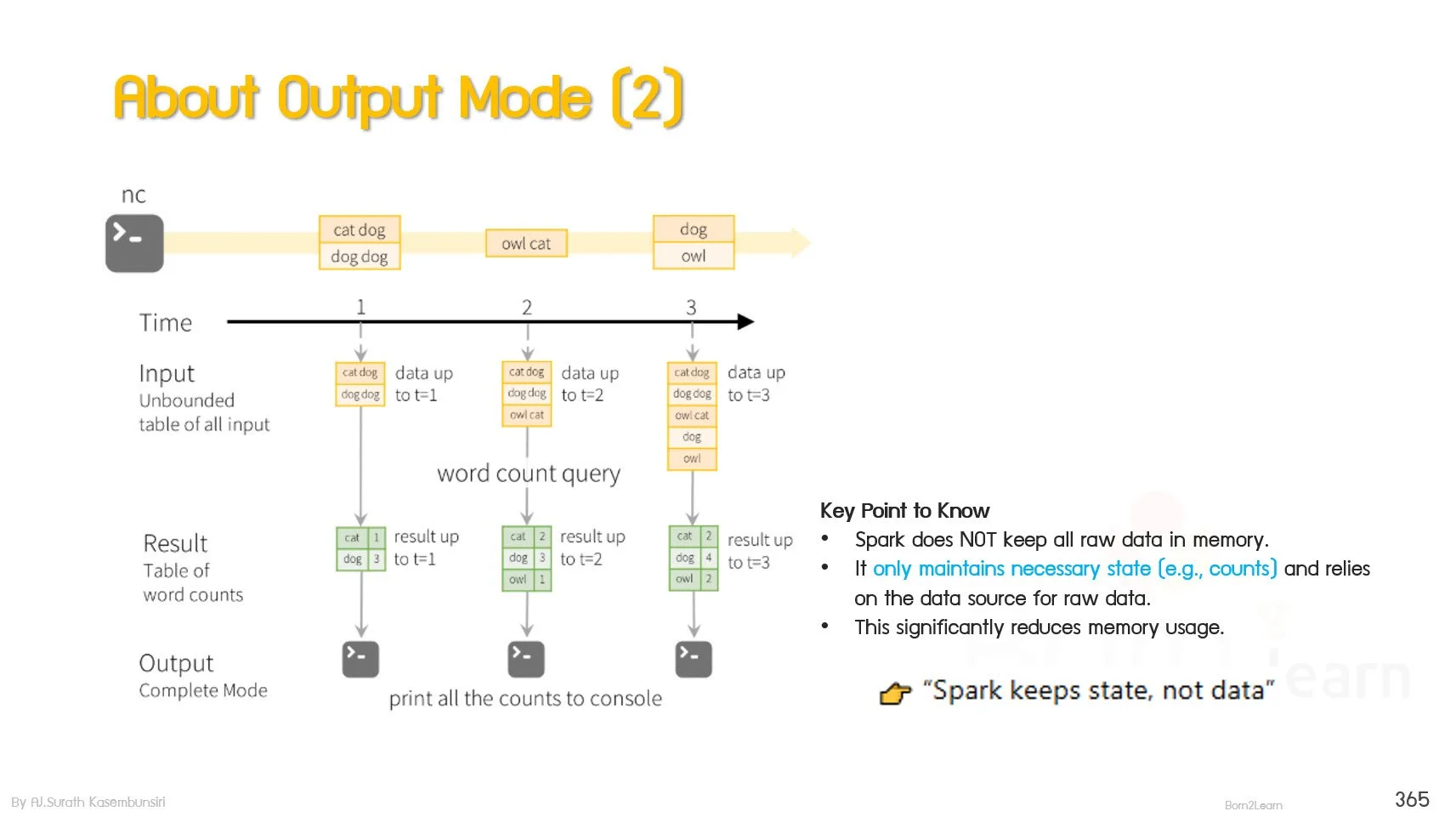
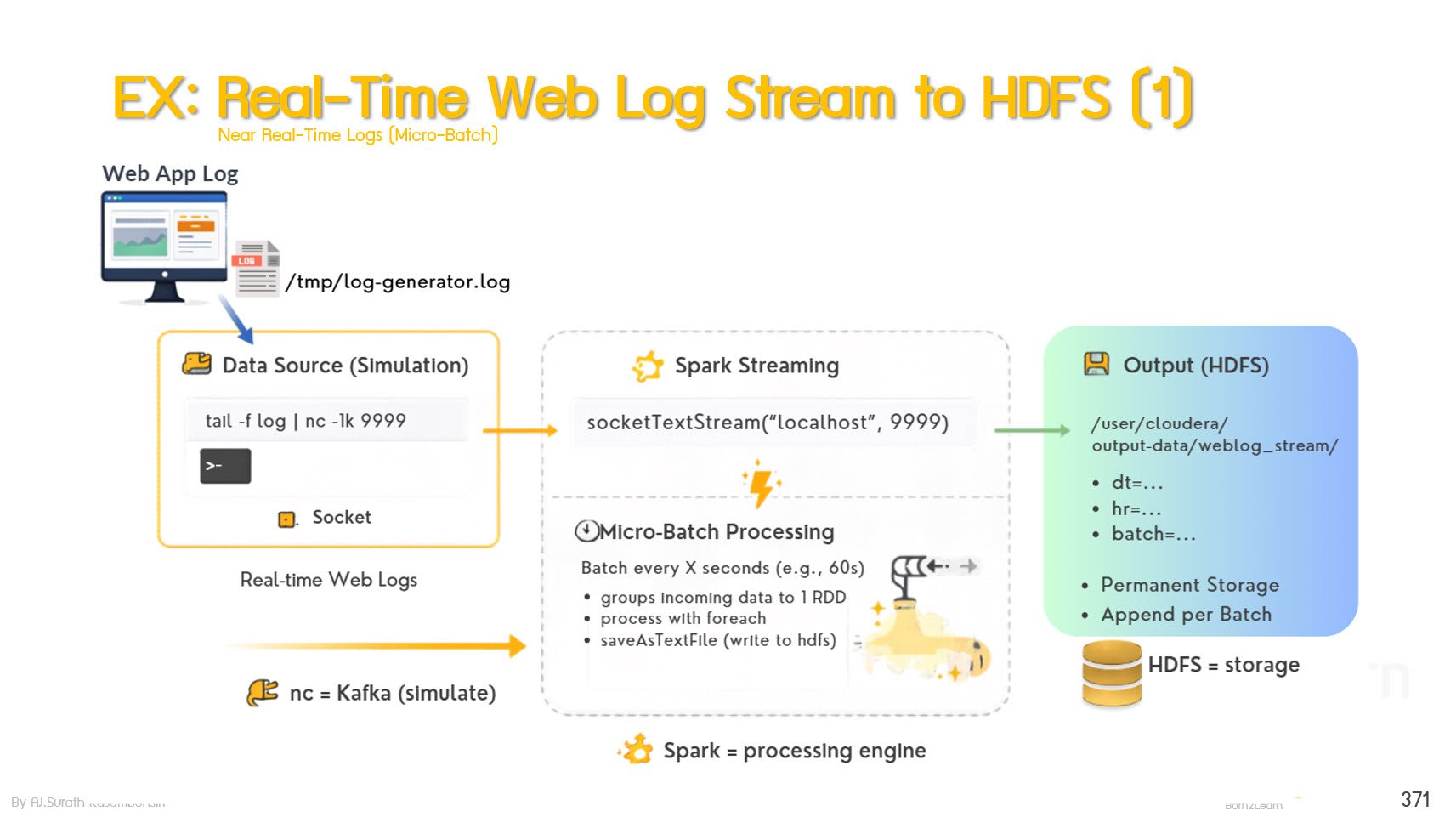
· Real-Time Processing with Spark Streaming
Spark Streaming Fundamentals
Core Components of Spark Streaming
Input Sources for Streaming Data
Output Modes and Sink Systems
Real-Time Data Processing Use Case
· Data Integration with Sqoop
Sqoop Overview
Sqoop Use Cases
Sqoop Architecture
Sqoop Import from RDBMS to HDFS
Parallel Import Concepts
Import Data into Hive Tables
Incremental Data Import
Export Data from HDFS to RDBMS